
Python
Python
Python 数据类型
Number(数字)
int、float、bool、complex(复数)
数字常用函数
ceil(x) 函数返回一个大于或等于 x 的的最小整数。
math.ceil(-45.17) : -45
math.ceil(100.12) : 101
math.ceil(100.72) : 101
math.ceil(math.pi) : 4
abs() 函数返回数字的绝对值。
abs(-40) : 4
abs(100.10) : 100.1
floor(x) 返回数字的下舍整数,小于或等于 x。
math.floor(-45.17) : -46
math.floor(100.12) : 100
math.floor(100.72) : 100
math.floor(math.pi) : 3
max() 方法返回给定参数的最大值,参数可以为序列。
min() 方法返回给定参数的最小值,参数可以为序列。
1.random.random():**会随机生成0-1之间的小数
2.random.uniform(min,max):**会随机生成 min - max 之间的小数,其中min 和 max 的位置可以互换而不会报错:
3.random.randint(min,max):**随机生成 min - max 之间的整数,如果min > max 会报错:
4.random.choice(元祖/列表/range()/字符串):** 会从给定的元祖/列表/range()/字符串 中随机挑选出一个元素:(由于该操作不会对给定对象中的元素进行修改,所以对象类型可以是不可变类型,例如元祖和字符串):
5.random.randrange(min,max,tap_num):** 会在 min - max 之间随机产生一个数,其中以 tap_num作为选取数字的间隔:(这样可以选取某一范围内的奇数和偶数):
6.random.sample(元祖/列表/字符串/range,num):会从给定对象的所有元素中随机选取num个元素:
7.random.shuffle(list(可变变量)):**
8.seed() 方法改变随机数生成器的种子,可以在调用其他随机模块函数之前调用此函数。random.seed ( [x] )
round()** 方法返回浮点数 x 的四舍五入值
round(70.23456) : 70
round(56.659,1) : 56.7
round(80.264, 2) : 80.26
round(100.000056, 3) : 100.0
round(-100.000056, 3) : -100.0
字符常用函数
mystr.find(str, o,len(mystr)
mystr.find("itcast") 找不到返回-1
mystr.rfind("itcast") 找不到返回-1
mystr.index("itcast",0,10) 找不到回报异常
mystr.rindex("itcast",0,10) 找不到回报异常
mystr.count("itcast",0,10)
mystr.replace("原来字符","替换后的字符",1)
mystr.split("",2)已空字符串分隔前面两个
mystr.splitlines() 按照行分隔\n返回一个包含各行作为元素的列
mystr.capitalize() 把字符串的第一个字符大写
mystr.title() 把字符串的第每个字母大写
mystr.startswith("hello") 检查字符串是否以hello开头,返回Bool
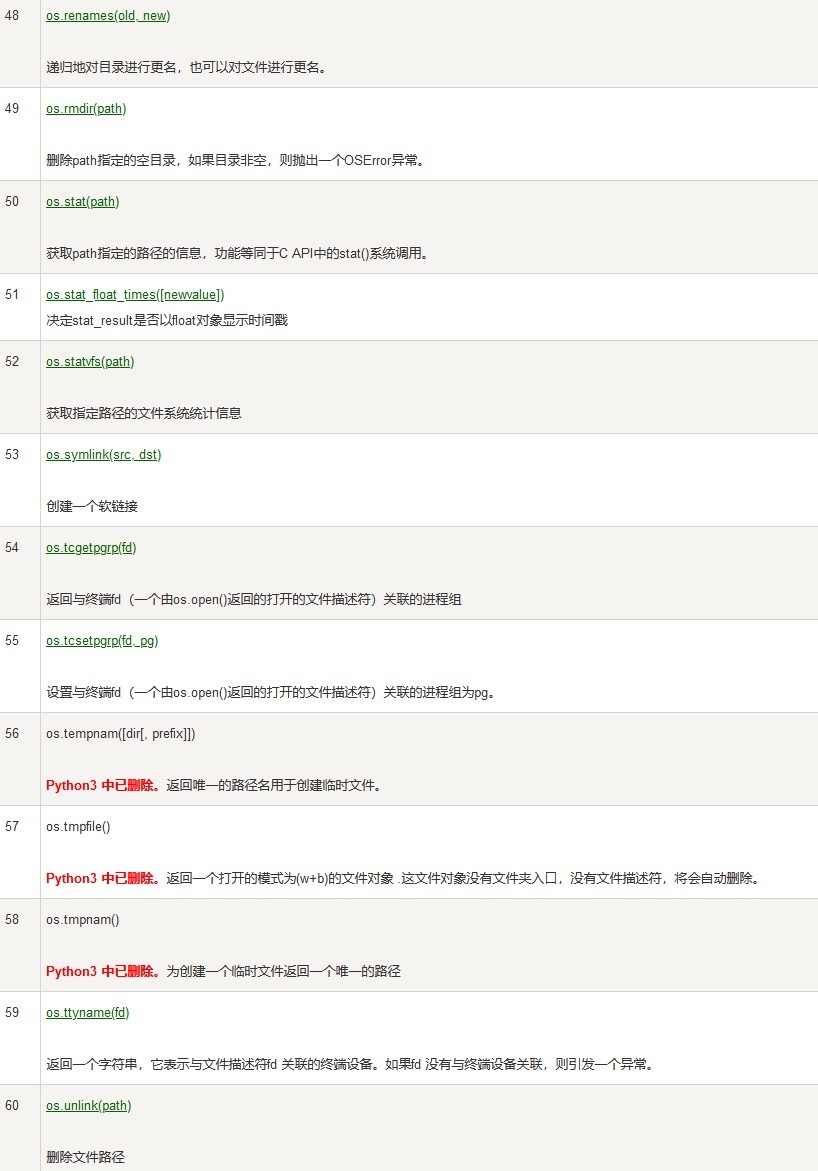
mystr.endswith("hello") 检查字符串是否以hello结尾,返回Bool
mystr.lower(). 所有大写字符为小写
mystr.upper() 所有小写字符为大写
mystr.ljust(10) 返回一个原字符串左对齐,并使用空格填充值长度10的新字符串
mystr.rjust(10) 返回一个原字符串右对齐,并使用空格填充值长度10的新字符串
mystr.center(10) 返回一个原字符串右对齐,并使用空格填充值长度10的新字符串两边
mystr.lstrip() 删除左边的空白字符
mystr.rstrip() 删除右边的空白字符
mystr.strip() 删除左右两边的空白字符
mystr.partition("it1ast") 以itcast从左边开始查找 分隔前,itcast,后三部分
mystr.rpartition("it1ast") 以itcast从右边边开始查找 分隔前,itcast,后三部分
mystr.isalpha() 字符都是字母,返回True
mystr.isdigit() 都是数字,返回True
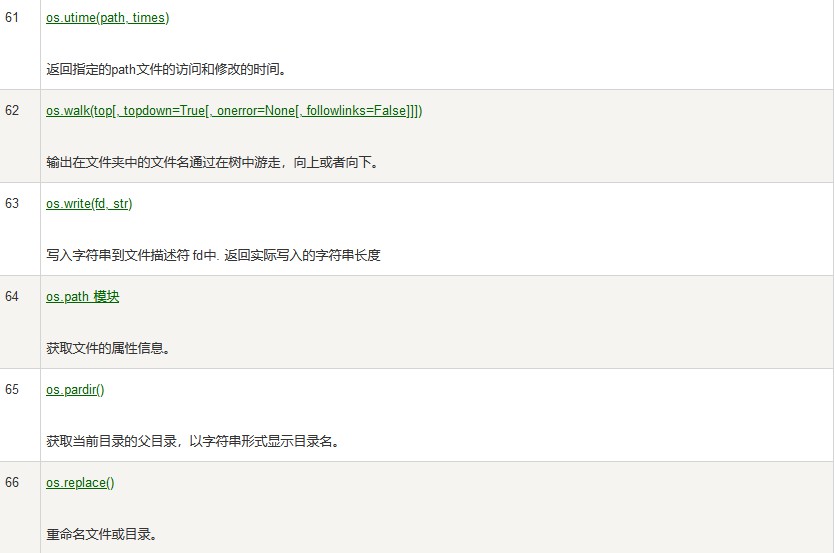
mystr.isalnum() 所有字符都是字母或数字返回True
mystr.isspace() 只包含空格返回True
"_t".join(mystr) 一个列表包含多个字符,在每个字符后面加上下划线
isinstance (a,int) True
mystr[起始:结束:步长]
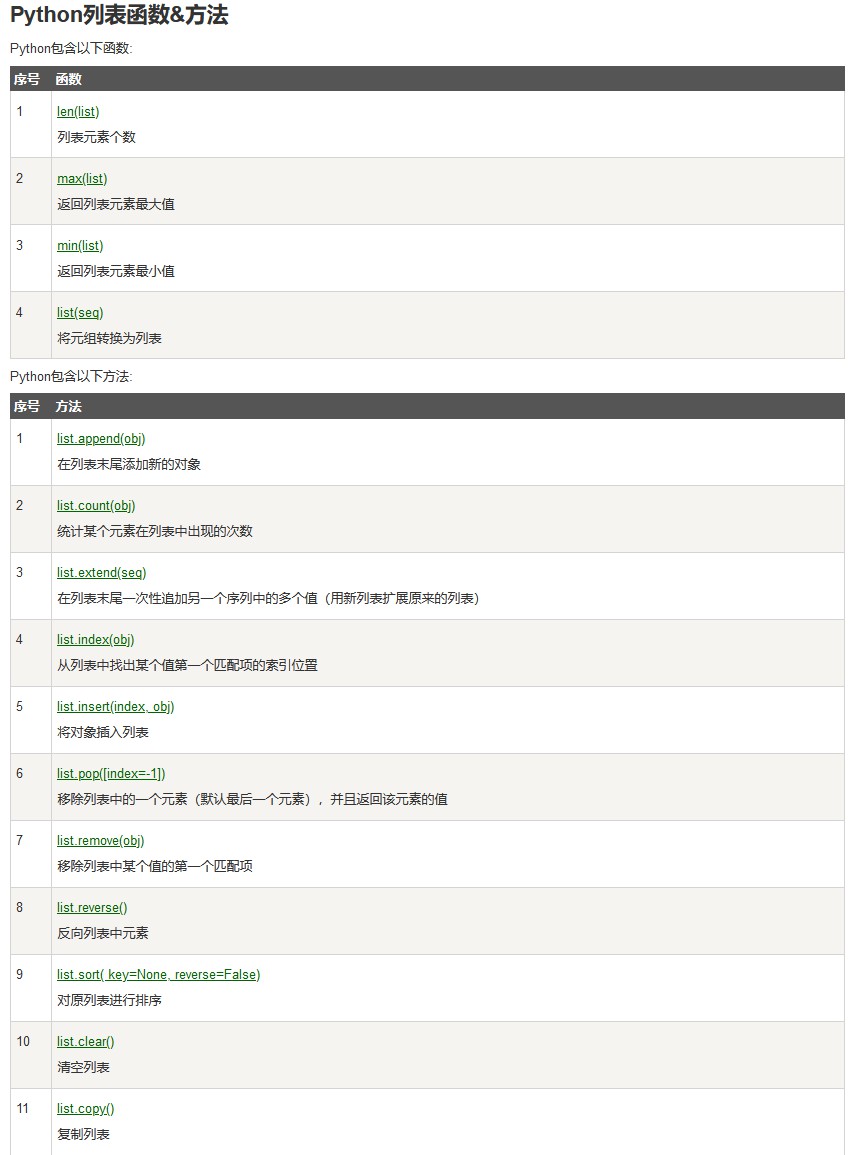
List(列表)
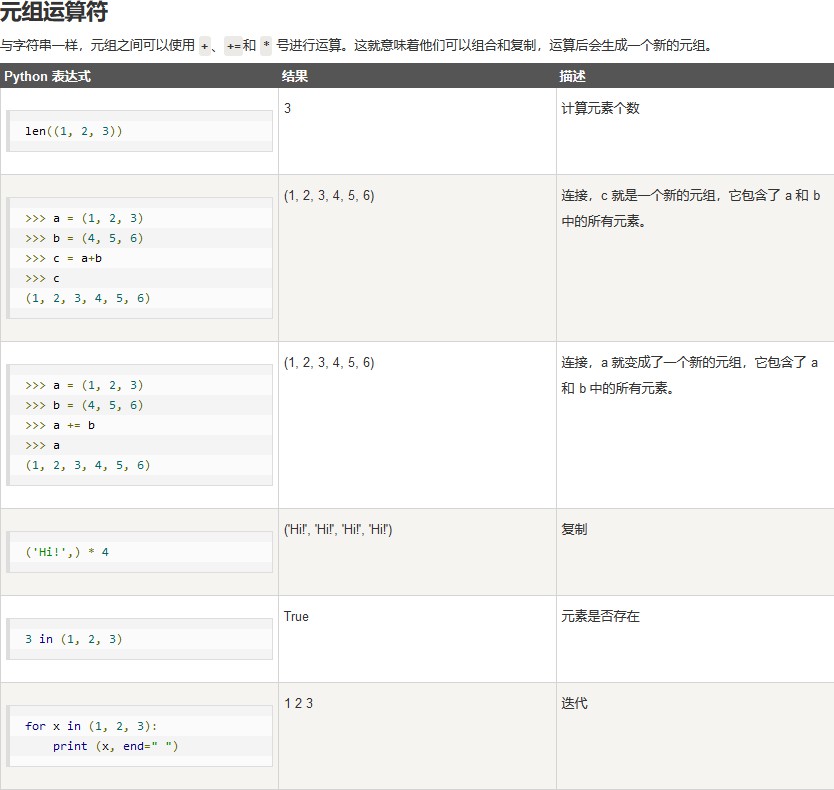
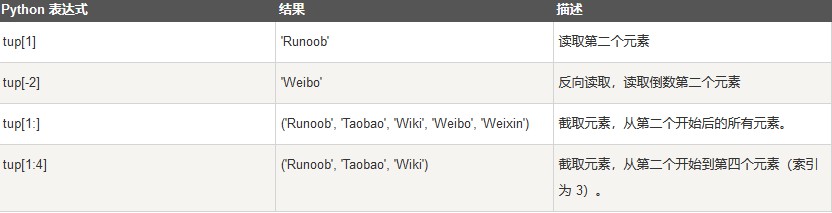
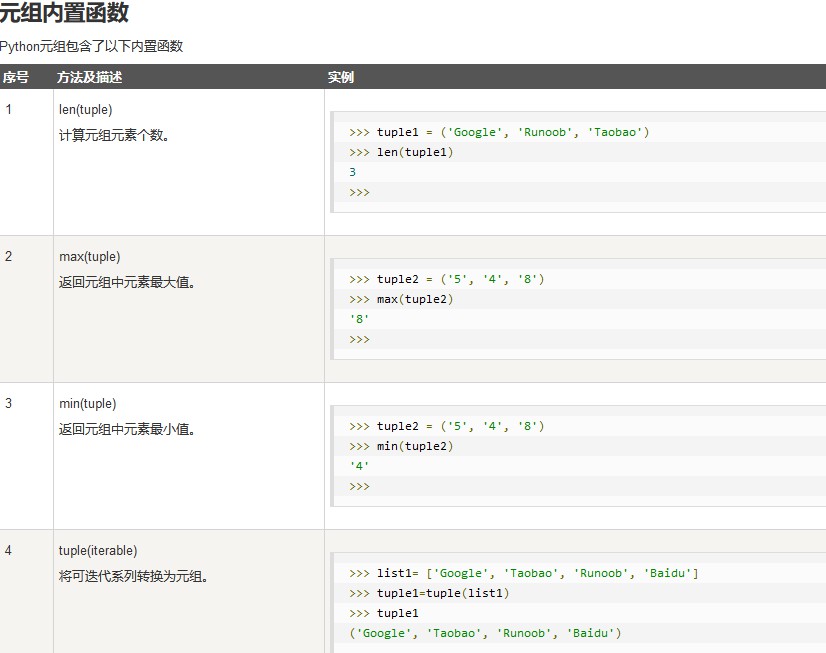
Tuple(元组)
Dictionary(字典)
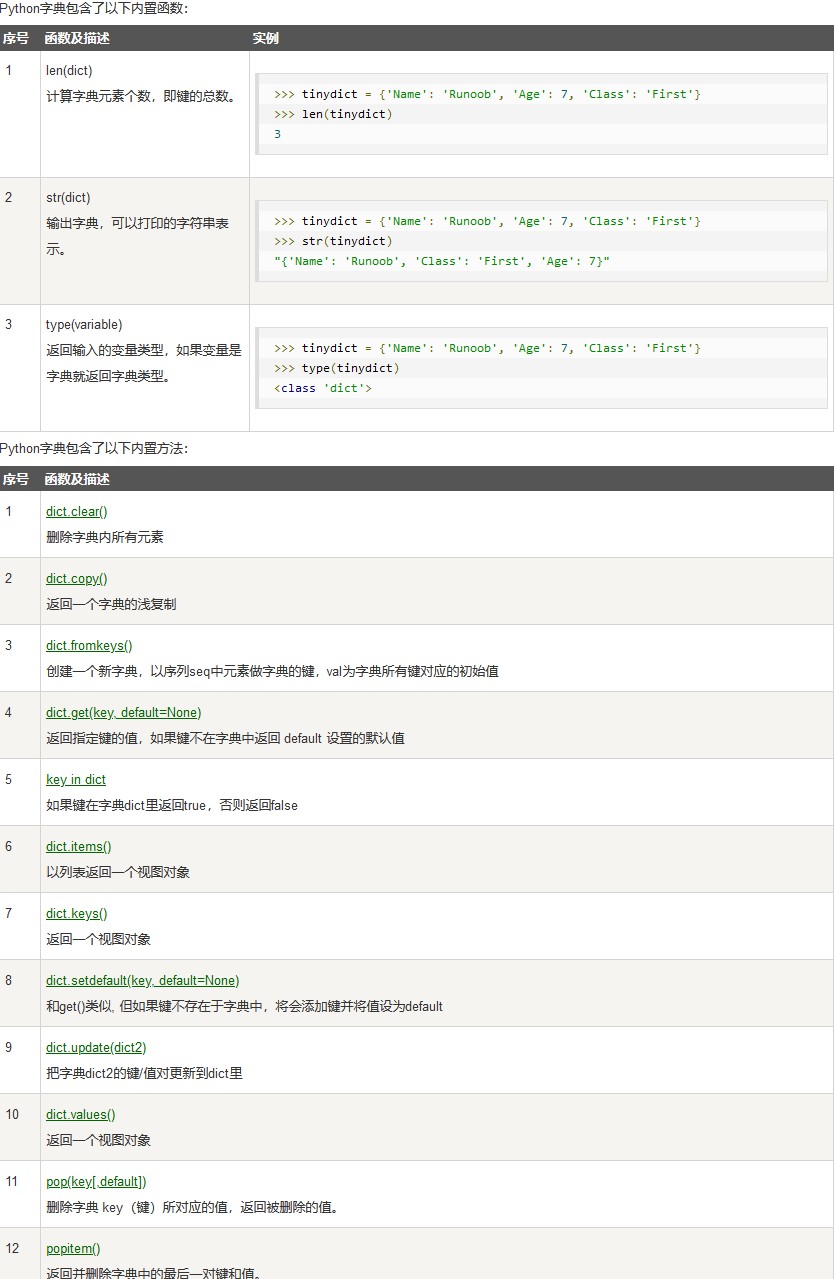
[键名]取值时若键名不在字典中则程序报错
# 新建一个字典
code_dict = {
"北京":100000,
"上海":200000,
"广州":510000
}
print(code_dict['成都'])
>>KeyError: '成都'
get函数取值时若键名不在字典中则程序返回None
# 新建一个字典
code_dict = {
"北京":100000,
"上海":200000,
"广州":510000
}
print(code_dict.get('成都'))
>>None
updata更新
a = {'one': 1, 'two': 2, 'three': 3}
a.update({'one': 4.5, 'four': 9.3})
a['one']=2
a['five']=11
print(a)
>>{'one': 2, 'two': 2, 'three': 3, 'four': 9.3, 'five': 11}
del tinydict['Name'] # 删除键 'Name'
tinydict.clear() # 清空字典
del tinydict # 删除字典
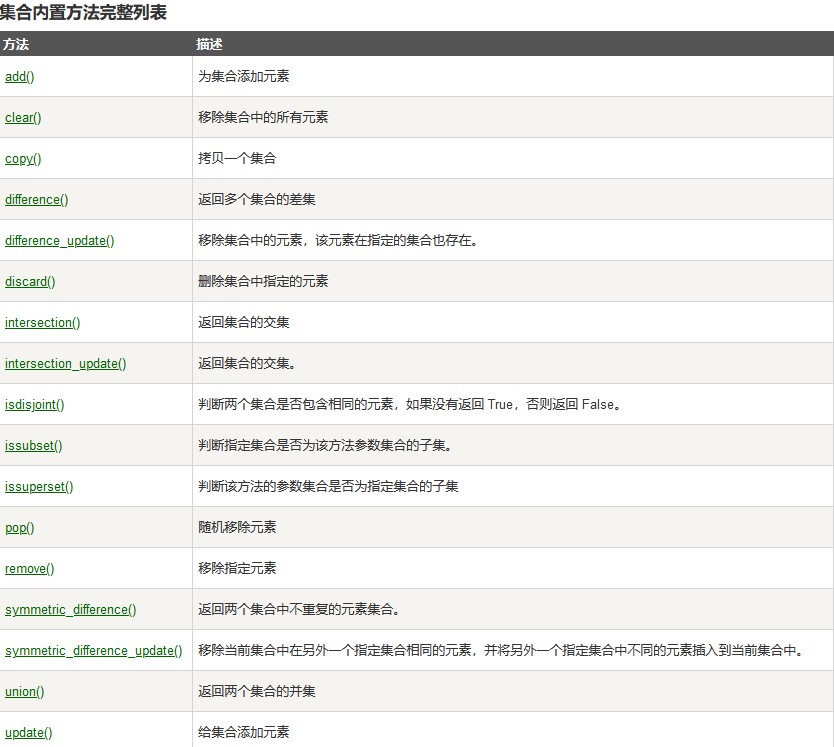
Set(集合)
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
set(value)
> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
### 1、添加元素
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.add("Facebook")
>>> print(thisset)
{'Taobao', 'Facebook', 'Google', 'Runoob'}
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.update({1,3})
>>> print(thisset)
{1, 3, 'Google', 'Taobao', 'Runoob'}
>>> thisset.update([1,4],[5,6])
>>> print(thisset)
{1, 3, 4, 5, 6, 'Google', 'Taobao', 'Runoob'}
>>>
### 2、移除元素
>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.remove("Taobao")
>>> print(thisset)
{'Google', 'Runoob'}
>>> thisset.remove("Facebook") # 不存在会发生错误
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Facebook'
>>>
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.discard("Facebook") # 不存在不会发生错误
>>> print(thisset)
{'Taobao', 'Google', 'Runoob'}
我们也可以设置随机删除集合中的一个元素,语法格式如下:
thisset = set(("Google", "Runoob", "Taobao", "Facebook"))
x = thisset.pop()
### 3、计算集合元素个数
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> len(thisset)
### 4、清空集合
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> thisset.clear()
>>> print(thisset)
输出结果:set()
### 5、判断元素是否在集合中存在 判断元素 x 是否在集合 s 中,存在返回 True,不存在返回 False。
>>> thisset = set(("Google", "Runoob", "Taobao"))
>>> "Runoob" in thisset
True
>>> "Facebook" in thisset
False
>>>
判断类型
isinstance 和 type 的区别在于:
type()不会认为子类是一种父类类型。
isinstance()会认为子类是一种父类类型。
>>> a = 111 >>> isinstance(a, int) True >>>>>> class A: ... pass ... >>> class B(A): ... pass ... >>> isinstance(A(), A) True >>> type(A()) == A True >>> isinstance(B(), A) True >>> type(B()) == A False**注意:**Python3 中,bool 是 int 的子类,True 和 False 可以和数字相加, True1、False0 会返回 True,但可以通过 is 来判断类型。
>>> issubclass(bool, int) True >>> True==1 True >>> False==0 True >>> True+1 2 >>> False+1 1 >>> 1 is True False >>> 0 is False False注意:
- 1、Python可以同时为多个变量赋值,如a, b = 1, 2。
- 2、一个变量可以通过赋值指向不同类型的对象。
- 3、数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数。
- 4、在混合计算时,Python会把整型转换成为浮点数。
数据类型转换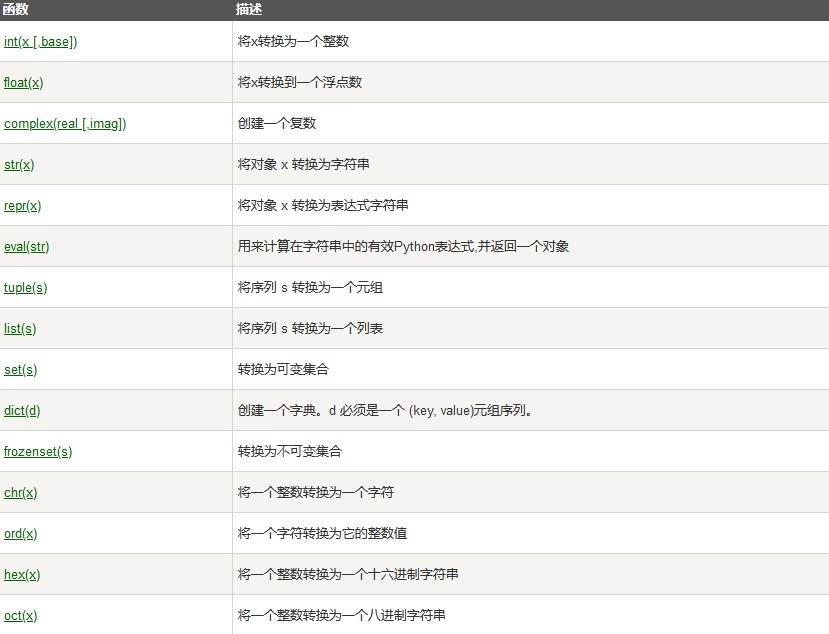
运算符
算数运算符
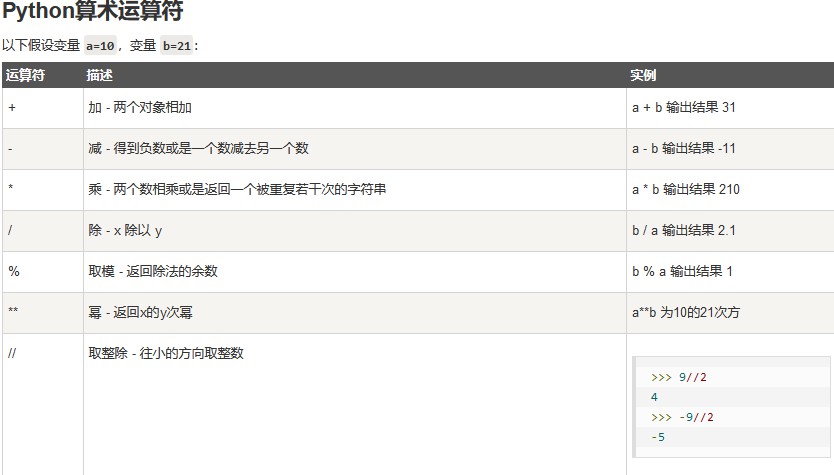
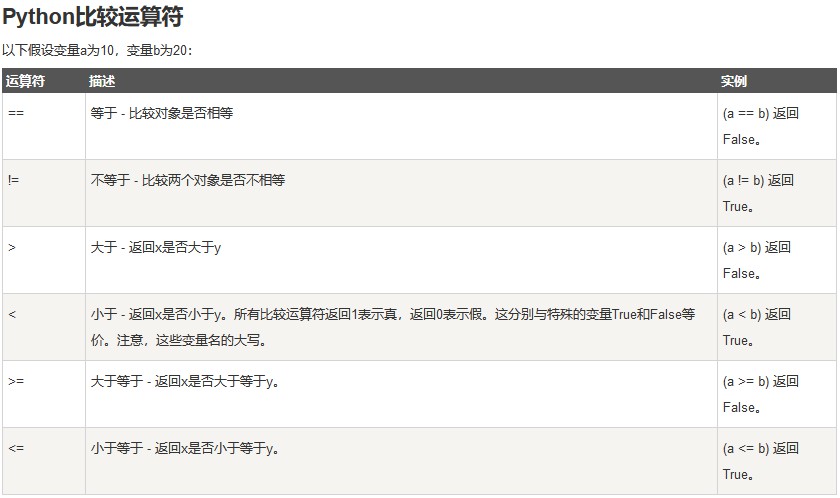
赋值运算符
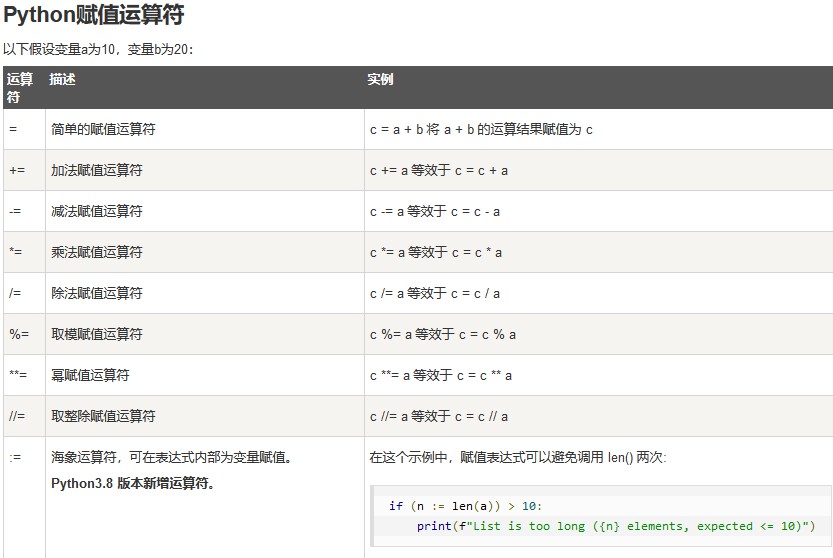
逻辑运算符
位运算符
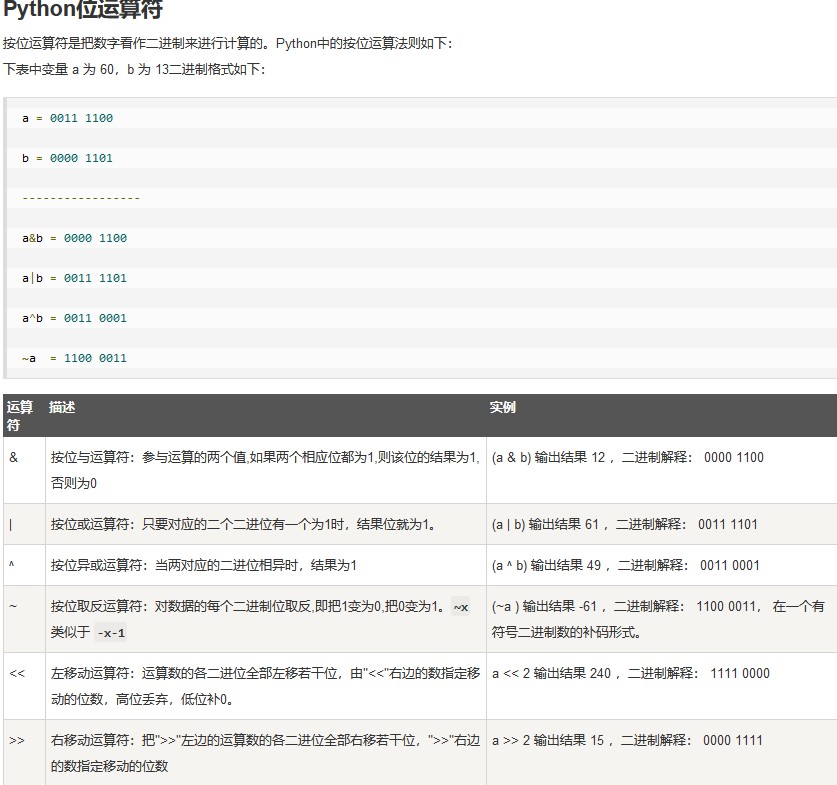
成员运算符
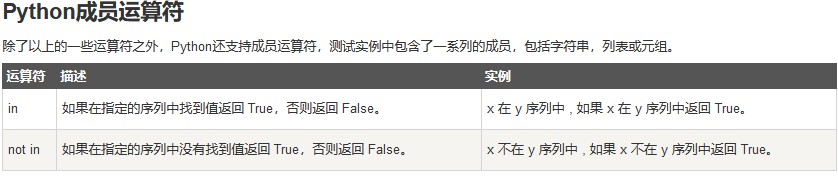
身份运算符

运算符优先级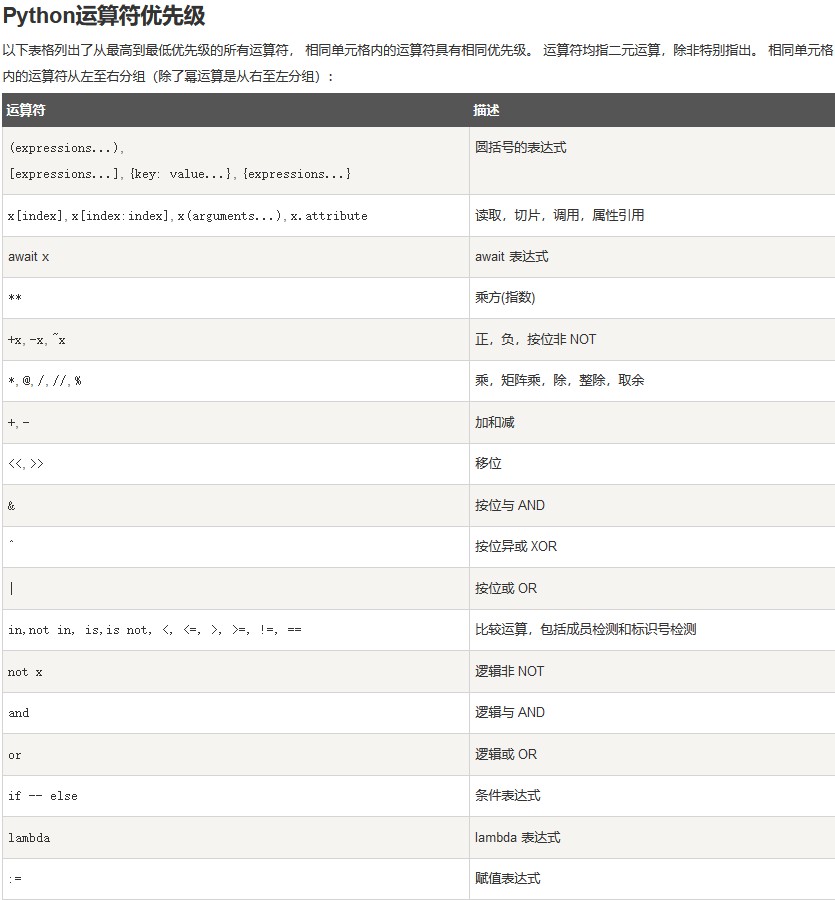
语法
条件控制 if
age = int(input("请输入你家狗狗的年龄: "))
print("")
if age <= 0:
print("你是在逗我吧!")
elif age == 1:
print("相当于 14 岁的人。")
elif age == 2:
print("相当于 22 岁的人。")
elif age > 2:
human = 22 + (age -2)*5
print("对应人类年龄: ", human)
### 退出提示
input("点击 enter 键退出")
if 表达式1:
语句
if 表达式2:
语句
elif 表达式3:
语句
else:
语句
elif 表达式4:
语句
else:
语句
循环控制while
while 判断条件(condition):
执行语句(statements)……
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
print("1 到 %d 之和为: %d" % (n,sum))
while <expr>:
<statement(s)>
else:
<additional_statement(s)>
如果 while 后面的条件语句为 false 时,则执行 else 的语句块。
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
>>
0 小于 5
1 小于 5
2 小于 5
3 小于 5
4 小于 5
5 大于或等于 5
循环for
for <variable> in <sequence>:
<statements>
else:
<statements>
ites = ["Baidu", "Google","Runoob","Taobao"]
for site in sites:
if site == "Runoob":
print("教程!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!")
当循环执行完毕(即遍历完 iterable 中的所有元素)后,会执行 else 子句中的代码,如果在循环过程中遇到了 break 语句,则会中断循环,此时不会执行 else 子句。
range() 函数
>>>for i in range(-10, -100, -30) :
print(i)
>>>list(range(5))
[0, 1, 2, 3, 4]
>>>
break 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
continue 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环
n = 5
while n > 0:
n -= 1
if n == 2:
continue
print(n)
print('循环结束。')
>>
4
3
1
0
循环结束。
Python 推导式
- 列表(list)推导式
- 字典(dict)推导式
- 集合(set)推导式
- 元组(tuple)推导式
Python 推导式是一种独特的数据处理方式,可以从一个数据序列构建另一个新的数据序列的结构体。
[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]
[表达式 for 变量 in 列表 if 条件]
[out_exp_res for out_exp in input_list if condition]
>>> names = ['Bob','Tom','alice','Jerry','Wendy','Smith']
>>> new_names = [name.upper()for name in names if len(name)>3]
>>> print(new_names)
['ALICE', 'JERRY', 'WENDY', 'SMITH']
>> dic = {x: x**2 for x in (2, 4, 6)}
>>> dic
{2: 4, 4: 16, 6: 36}
>>> type(dic)
<class 'dict'>
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'d', 'r'}
>>> type(a)
<class 'set'>
>>> a = (x for x in range(1,10))
>>> a
<generator object <genexpr> at 0x7faf6ee20a50> # 返回的是生成器对象
>>> tuple(a) # 使用 tuple() 函数,可以直接将生成器对象转换成元组
(1, 2, 3, 4, 5, 6, 7, 8, 9)
迭代器与生成器
是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
>>> list=[1,2,3,4]
>>> it = iter(list) # 创建迭代器对象
>>> print (next(it)) # 输出迭代器的下一个元素
1
>>> print (next(it))
2
>>>
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
>>1 2 3 4
函数
def 函数名(参数列表):
函数体
# 计算面积函数
def area(width, height):
return width * height
def print_welcome(name):
print("Welcome", name)
print_welcome("Runoob")
w = 4
h = 5
print("width =", w, " height =", h, " area =", area(w, h))
参数传递
必需参数
关键字参数
默认参数
def printinfo( name, age = 35 ):不定长参数
def fun1(a, b, *args, **kwargs):
print(a)
print(b)
print(args)
print(kwargs)
return a,b,args,kwargs
tup = (11,22,33)
dic = {"name":"hello", "age":20}
>>
1
2
(11, 22, 33)
{'name': 'hello', 'age': 20}
(1, 2, (11, 22, 33), {'name': 'hello', 'age': 20})
类
# 创建一个类 人类
class people():
# 定义类属性
type= "中国人"
# 定义实例属性
def __init__(self,name):
self.name= name
# 定义实例方法
def eat(self):
print("我想吃饭!")
# 类方法 就是在普通方法前面加一个关键字
@classmethod
def change1(cls,n1):
cls.type = n1
# 创建一个实例对象
p1 = people("狗蛋")
# 触发类方法
# 触发类方法有两种
# p1.change1("美国人")
# print(p1.type)
people.change1("美国人")
print(p1.type)
实现类
# 定义 动物
class Animal:
# 实例属性和实例方法
def __init__(self,name , age ,sex ):
self.name = name
self.age = age
self.sex = sex
# 定义方法
def eat(self):
print(self.name, "要吃好的吃贵的")
# 定义狗类
class Dog(Animal):
# 实例属性和实例方法
# 实例方法
def bark(self):
print(self.name,"汪汪叫")
class poodle(Dog):
# 定义实例方法
def bark(self):
print("喵喵叫")
# 实例对象
p1 = poodle("泰迪1",2 ,"公")
# 实例属性
print(p1.name)
# 实例方法
p1.eat()
p1.bark()
# 实例对象
p2 = poodle("泰迪2","3","母")
# 实例属性
print(p2.age)
# 实例方法
p2.bark()
重写父类
# 如果子类 方法和父类方法同名 默认以子类为准
# 但是在工作一般我们想保留父类方法 就需要方法重写
# 重写父类方法有三种方式
# 定义dog
class Dog():
# 实例属性
def __init__(self,age ,name):
self.age = age
self.name = name
# 实例方法
def eat(self):
print("我要吃好的--骨头")
# 定义子类
class poodle(Dog):
# 定义方法
def eat(self):
# 可以保留父类方法 子类和父类方法同名以子类为主
# 第一种保留父类方法
# super(poodle, self).eat()
# 第二种保留父类方法
# super().eat()
# 第三种重写父类方法
Dog.eat(self)
print("我吃狗粮")
# 实例对象
p1= poodle(2,"泰迪11")
# 调用实例方法
p1.eat()
# super(子类,self).eat() 三种方法
# super().eat()|
# Dog.eat(self) Dog是实例化的父类对象
多继承
# 多继承
# 一个子类可以继承多个父类
# 神仙类 # 狗类 # 神狗
class God(object):
# # 定义实例属性
# def __init__(self, age , name ):
# self.age = age
# self.name = name
# 定义实例方法
def fly(self):
print("翱翔到天黑")
def speak(self):
print("说人话")
# 定义一个狗
class Dog(object):
def eat(self):
print("吃狗粮")
def speak(self):
print("说兽语")
# 定义神狗
class Mounts(God,Dog):
# 定义方法
def speak(self):
num1 = input("1 表示说人话 2 表示说兽语 ")
if num1 == "1":
# 保留父类方法
God.speak(self)
elif num1 == "2":
# 保留父类方法
Dog.speak(self)
else:
print("当前输入有误~")
# 创建一个神狗
m1 =Mounts()
# 实例方法
m1.fly()
m1.eat()
m1.speak()
# 多继承的语法规则
# 子类(父类1,父类2)
# 如果多个父类的方法同名 按照继承顺序
# 查看继承的顺序
# 子类.__mro__
print(Mounts.__mro__)
私有属性
# 私有属性外部一般不运行访问 如果外面想使用私有属性就看类的内部是否提供方法
# 创建一个类
class People:
# 实例属性
# 实例方法
def __init__(self,name,age,sex):
self.name = name
self.__age = age
self.__sex= sex
# 定义私有方法
def __drink(self):
print(self.name ,"想喝点水了")
# 获取私有属性
def get_age(self):
# 在类的内部执行私有方法
People.__drink(self)
return self.__age
# 修改私有属性
def set_age(self,num1):
self.__age = num1
# 实例对象
p1 = People("翠花",18,"女")
# 访问实例属性
# print(p1.__sex) # 外部无法访问私有属性
# 设置私有属性 就是在属性的前面加两个 __
# 此时外部就无法直接访问这个私有属性
# 外部一般无法直接访问私有属性就看类的内部是否提供方法
# 访问实例方法
num1 = p1.get_age()
print(num1)
#设置私有属性
p1.set_age(19)
# 修改之后再获取
num2= p1.get_age()
print(num2)
# num2 = p1.get_age()
# print(num2)
多态
# 多态 指的就是事物的多种状态
# 就是在使用父类的方法也可以使用子类 必须子类和父类需要有继承关系
class meat(object):
# 实例属性 和实例方法
def __init__(self):
self.type = "肉"
# 定义一个类汉堡包
class hanbs(meat):
def __init__(self):
# 重写父类的属性
meat.__init__(self)
# self.type =self.type+ "蔬菜"+ "面包"
self.type += "蔬菜"+"面包"
# 定义人类
class people():
# 定义实例方法
def eat(self,obj):
print("我想吃",obj.type)
# 实例的对象 肉
m1= meat()
# 定义一个汉堡包
h1 = hanbs()
# 实例对象一个人
p1 = people()
# 执行实例方法
p1.eat(m1)
p1.eat(h1)
鸭子类型
1.鸭子类型1
class Duck:
def quack(self):
print("嘎嘎嘎嘎。。。。。")
class Bird:
def quack(self):
print("bird imitate duck....")
class geese:
def quack(self):
print("doge imitate duck....")
def in_the_forest(duck):
duck.quack()
duck = Duck()
bird = Bird()
doge = geese()
for x in [duck, bird, doge]:
in_the_forest(x)
>>
嘎嘎嘎嘎。。。。。
bird imitate duck....
doge imitate duck....
鸭子类型要求每个class要有相同的方法
def in_the_forest(duck):
duck.quack()
2.鸭子类型2
class duck():
def walk(self):
print('I walk, i am a duck')
def swim(self):
print('i swim,i am a duck')
class geese():
def walk(self):
print('i walk like a duck')
def swim(self):
print('i swim like a duck')
class person():
def walk(self):
print('this one walk like a duck')
def swim(self):
print('this one walk like a duck')
def watch_duck(a):
a.walk()
a.swim()
small_duck = duck()
watch_duck(small_duck)
duck_like_geese = geese()
watch_duck(duck_like_geese)
duck_like_man = person()
watch_duck(duck_like_man)
>>
I walk, i am a duck
i swim,i am a duck
i walk like a duck
i swim like a duck
this one walk like a duck
this one walk like a duck
从上面可以看出,只要有watch_duck函数接收这个类的对象,然后并没有检查对象的类型,而是直接调用这个对象的walk和swim方法, 从上面可以看出,python鸭子类型的灵活性在于它关注的是这个所调用的对象是如何被使用的,而没有关注对象类型的本身是什么
3.鸭子类型3
# 执行测试用例的类
class BaseRun:
def run(self):
print("运作测试用例,生成txt格式的测试报告")
class HtmlRun(BaseRun):
def run(self):
print("运作测试用例,生成HTML格式的测试报告")#
class XMLRun(BaseRun):
def run(self):
print("运作测试用例,生成XML格式的测试报告")
class JsonRun(BaseRun):
def run(self):
print("运作测试用例,生成JsonRun格式的测试报告")
def main(obj: BaseRun):
"""测试执行的启动函数"""
# 此处省略若干行业务代码
obj.run()
if __name__ == '__main__':
b_obj = BaseRun()
main(b_obj)
html_obj = HtmlRun()
main(html_obj)
json_obj = JsonRun()
main(json_obj)
xml_json = XMLRun()
main(xml_json)
>>
运作测试用例,生成txt格式的测试报告
运作测试用例,生成HTML格式的测试报告
运作测试用例,生成JsonRun格式的测试报告
运作测试用例,生成XML格式的测试报告
文件
#文件的读操作
with open('input_filename.txt','r') as f:#r为标识符,表示只读
df=pd.read_csv(f)
print(f.read())
'''
其他标识符:
r: 以只读方式打开文件。
rb: 以二进制格式打开一个文件用于只读。
r+: 打开一个文件用于读写。文件指针将会放在文件的开头。
rb+:以二进制格式打开一个文件用于读写。
'''
#文件的写操作
with open('output_filename.csv', 'w') as f:
f.write('hello world')
'''
其他标识符:
w: 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb: 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+: 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+:以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a:打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab: 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+: 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+:以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
''' 4
注意
- 要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数
- 读取时调用read()将一次性读取文件的全部内容,如果文件有10G,内存就爆了,保险起见可反复调用read(size)方法,每次最多读取size个字节的内容。
- 调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。
- 根据需要调用:如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便
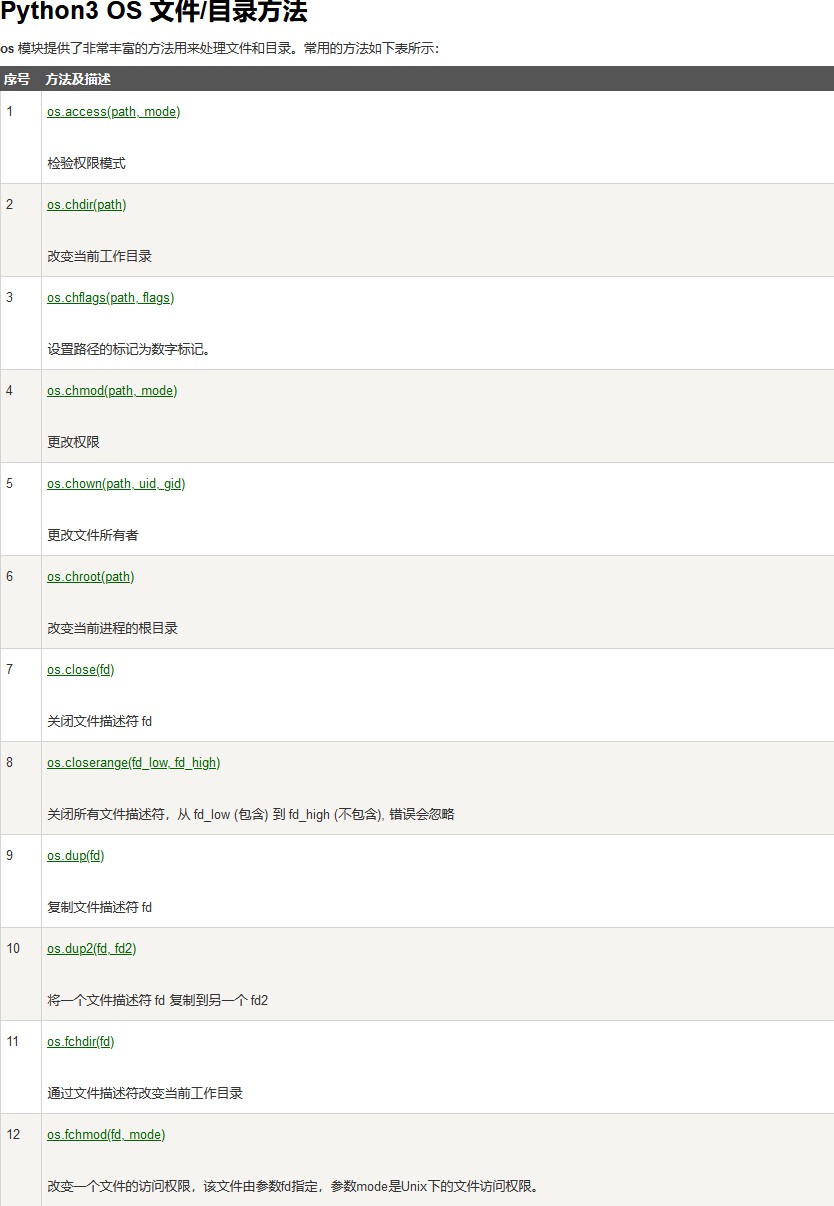

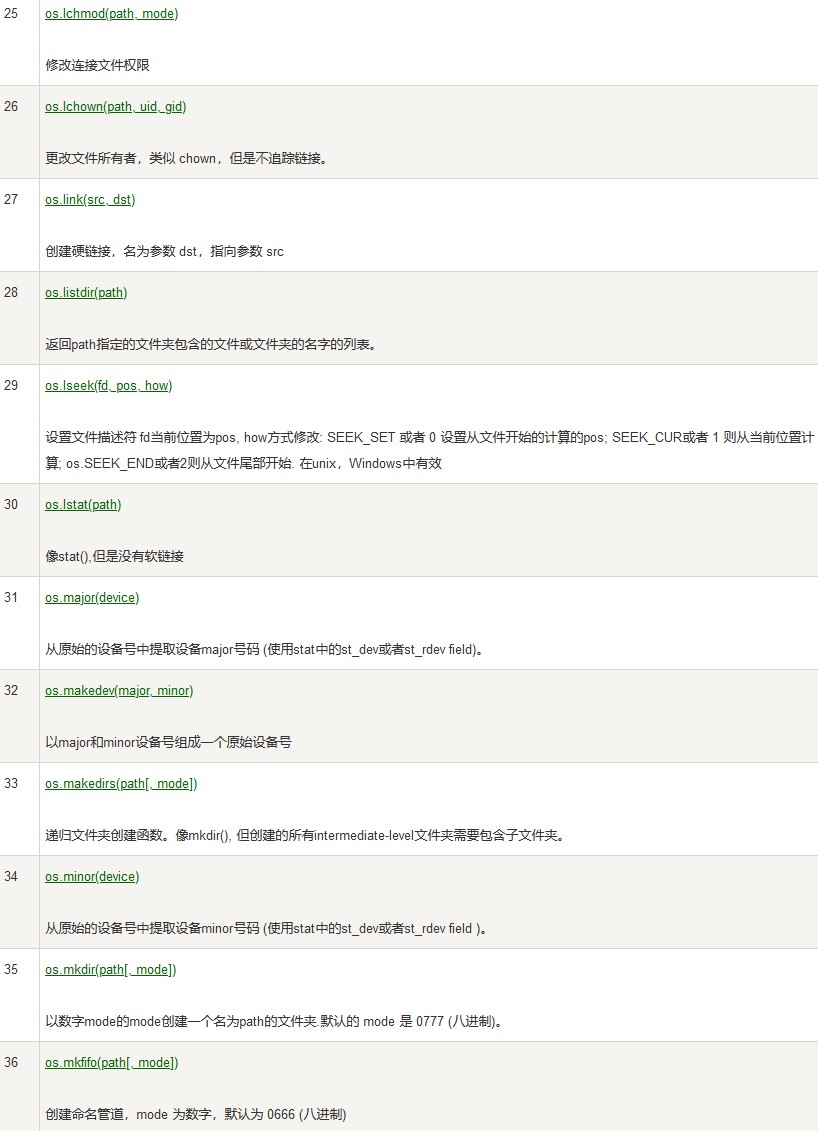
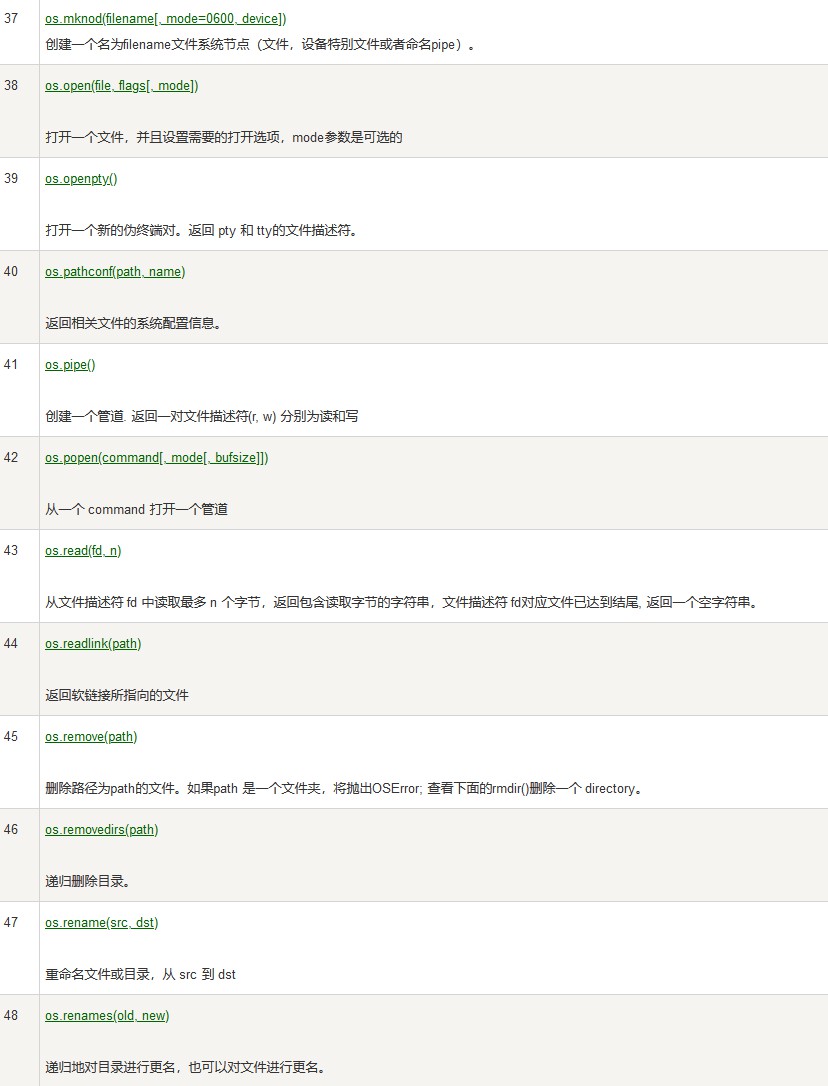
错误和异常
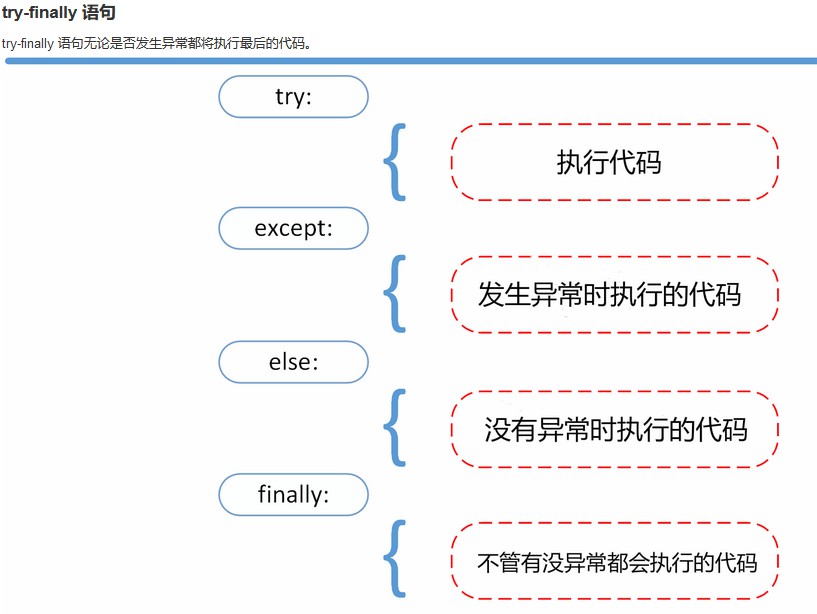
try:
runoob()
except AssertionError as error:
print(error)
else:
try:
with open('file.log') as file:
read_data = file.read()
except FileNotFoundError as fnf_error:
print(fnf_error)
finally:
print('这句话,无论异常是否发生都会执行。')
作用域
有四种作用域:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
规则顺序: L –> E –> G –> B。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
def inner():
i_count = 2 # 局部作用域
内置作用域是通过一个名为 builtin 的标准模块来实现的,但是这个变量名自身并没有放入内置作用域内,所以必须导入这个文件才能够使用它。在Python3.0中,可以使用以下的代码来查看到底预定义了哪些变量]()
>>> import builtins
>>> dir(builtins)
当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
>>
1
123
123
def ou`ter():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
>>
100
100
内置函数
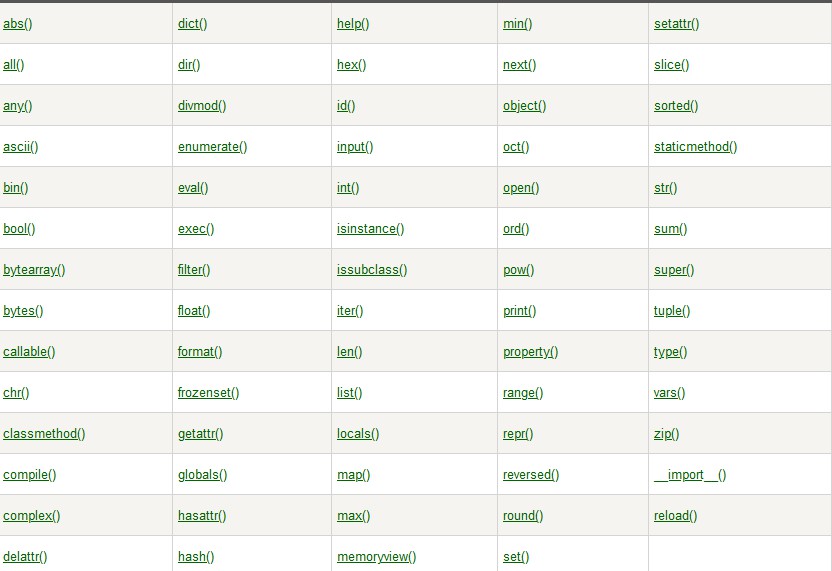
ord()
ord() 函数是 chr() 函数(对于 8 位的 ASCII 字符串)的配对函数,它以一个字符串(Unicode 字符)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值。
>>>ord('a')
97
>>> ord('€')
8364
>>>
chr()
chr() 用一个整数作参数,返回一个对应的字符。
>>>chr(0x30)
'0'
>>> chr(97)
'a'
>>> chr(8364)
'€'
sorted()
函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作
sorted(iterable, key=None, reverse=False)
>>> sorted([5, 2, 3, 1, 4])
[1, 2, 3, 4, 5] # 默认为升序
要进行反向排序,也通过传入第三个参数 reverse=True
>>> example_list = [5, 0, 6, 1, 2, 7, 3, 4]
>>> sorted(example_list, reverse=True)
[7, 6, 5, 4, 3, 2, 1, 0]
format
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
rint("网站名:{name}, 地址 {url}".format(**site))
filter()
filter(function, iterable)
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
tmplist = filter(is_sqr, range(1, 101))
newlist = list(tmplist)
print(newlist)
>>[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
zip()
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 返回一个对象
>>> zipped
<zip object at 0x103abc288>
>>> list(zipped) # list() 转换为列表
[(1, 4), (2, 5), (3, 6)]
>>> list(zip(a,c)) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> a1, a2 = zip(*zip(a,b)) # 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
>>> list(a1)
[1, 2, 3]
>>> list(a2)
[4, 5, 6]
>>>
map()
map(function, iterable, ...)
>>> def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
<map object at 0x100d3d550> # 返回迭代器
>>> list(map(square, [1,2,3,4,5])) # 使用 list() 转换为列表
[1, 4, 9, 16, 25]
>>> list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
>>>
reduce()
**注意:**Python3.x reduce() 已经被移到 functools 模块里,如果我们要使用,需要引入 functools 模块来调用 reduce() 函数:
reduce(function, iterable[, initializer])
def add(x, y) : # 两数相加
return x + y
sum1 = reduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5
sum2 = reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数
print(sum1)
print(sum2)
时间函数
import time
# 格式化成2016-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 格式化成Sat Mar 28 22:24:24 2016形式
print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y"))
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
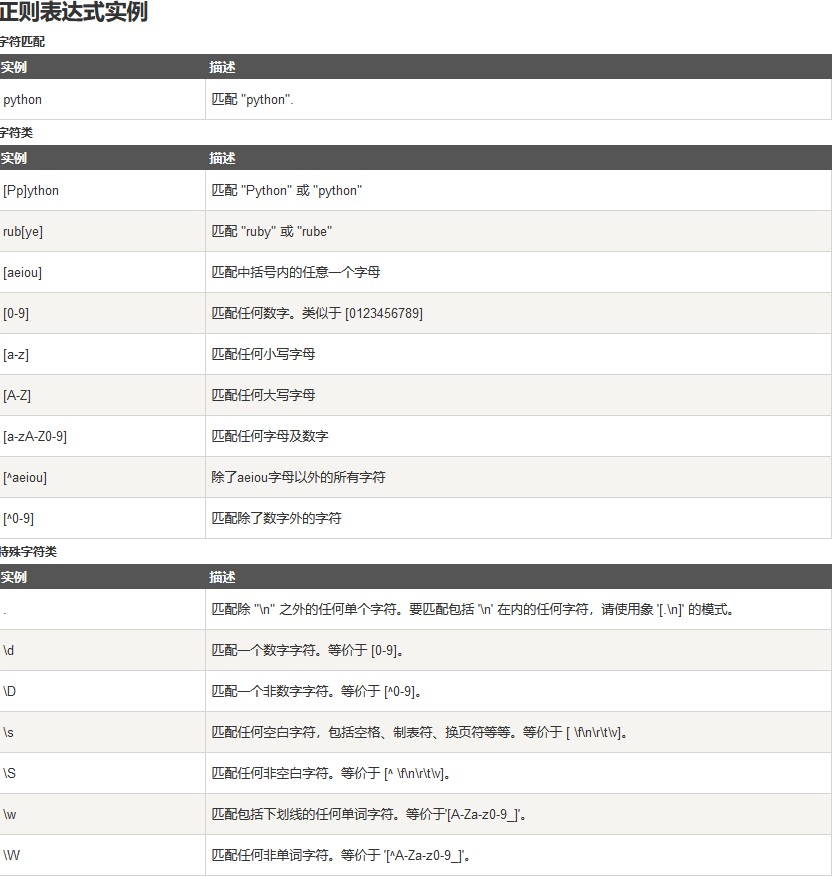
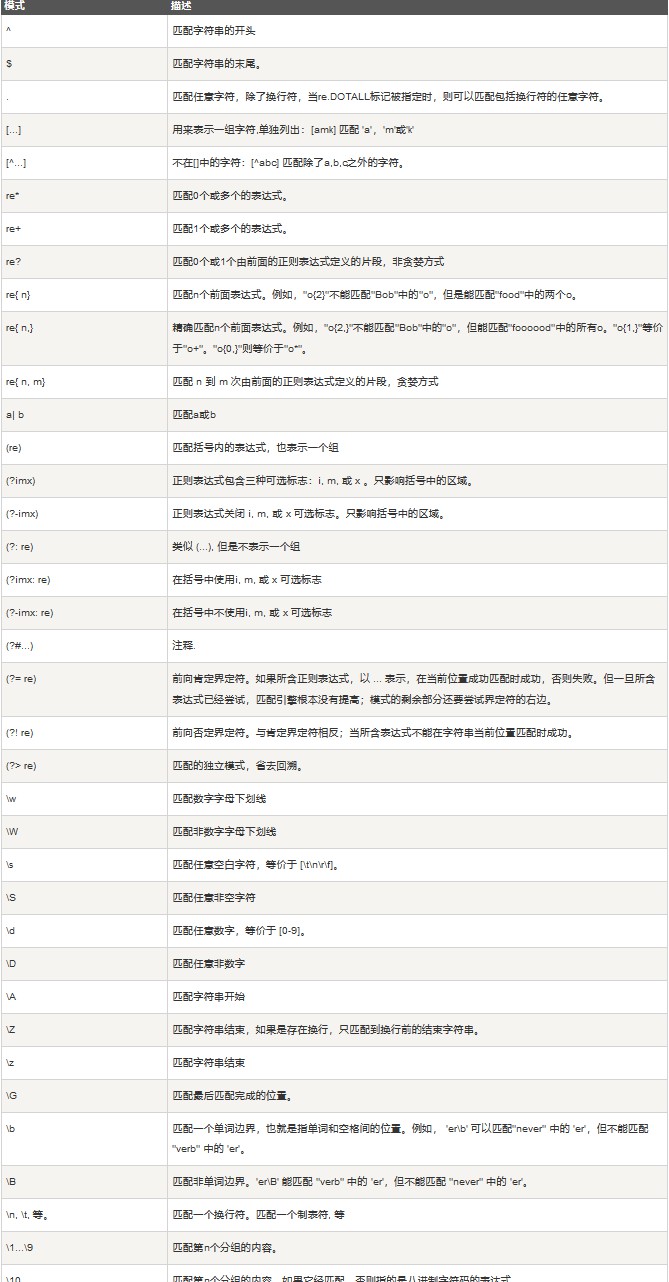
正则RE
match
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
>>
(0, 3)
None
search
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
>>
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
sub
re.sub(pattern, repl, string, count=0, flags=0)
>>import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
>>
电话号码 : 2004-959-559
电话号码 : 2004959559
compile
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
re.compile(pattern[, flags])
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print( m ) # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
findall
re.findall(pattern, string, flags=0)
或
pattern.findall(string[, pos[, endpos]])
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
import re
result1 = re.findall(r'\d+','runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(result3)
>>
['123', '456']
['123', '456']
['88', '12']
finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
re.finditer(pattern, string, flags=0)
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() )
>>
12
32
43
3
split
split 方法按照能够匹配的子串将字符串分割后返回列表
re.split(pattern, string[, maxsplit=0, flags=0])
>>>import re
>>> re.split('\W+', 'runoob, runoob, runoob.')
['runoob', 'runoob', 'runoob', '']
>>> re.split('(\W+)', ' runoob, runoob, runoob.')
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
>>> re.split('\W+', ' runoob, runoob, runoob.', 1)
['', 'runoob, runoob, runoob.']
>>> re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
['hello world']
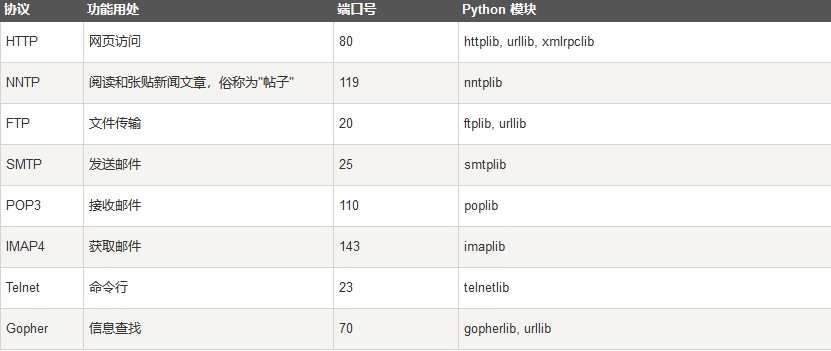
网络编程
python 提供了两个级别访问的网络服务。:
低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。
高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
socket.socket([family[, type[, proto]]])- family: 套接字家族可以是 AF_UNIX 或者 AF_INET
- type: 套接字类型可以根据是面向连接的还是非连接分为
SOCK_STREAM或SOCK_DGRAM - proto: 一般不填默认为0.
服务端
我们使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。
现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 port(端口)
#!/usr/bin/python3
# 文件名:server.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
serversocket = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
port = 9999
# 绑定端口号
serversocket.bind((host, port))
# 设置最大连接数,超过后排队
serversocket.listen(5)
while True:
# 建立客户端连接
clientsocket,addr = serversocket.accept()
print("连接地址: %s" % str(addr))
msg='欢迎访问菜鸟教程!'+ "\r\n"
clientsocket.send(msg.encode('utf-8'))
clientsocket.close()
客户端
接下来我们写一个简单的客户端实例连接到以上创建的服务。端口号为 9999。
socket.connect(hostname, port ) 方法打开一个 TCP 连接到主机为 hostname 端口为 port 的服务商。连接后我们就可以从服务端获取数据,记住,操作完成后需要关闭连接。
#!/usr/bin/python3
# 文件名:client.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
# 设置端口号
port = 9999
# 连接服务,指定主机和端口
s.connect((host, port))
# 接收小于 1024 字节的数据
msg = s.recv(1024)
s.close()
print (msg.decode('utf-8'))

json
json.dumps 与 json.loads 实例
import json
# Python 字典类型转换为 JSON 对象
data1 = {
'no' : 1,
'name' : 'Runoob',
'url' : 'http://www.runoob.com'
}
json_str = json.dumps(data1)
print ("Python 原始数据:", repr(data1))
print ("JSON 对象:", json_str)
# 将 JSON 对象转换为 Python 字典
data2 = json.loads(json_str)
print ("data2['name']: ", data2['name'])
print ("data2['url']: ", data2['url'])
>>
Python 原始数据: {'name': 'Runoob', 'no': 1, 'url': 'http://www.runoob.com'}
JSON 对象: {"name": "Runoob", "no": 1, "url": "http://www.runoob.com"}
data2['name']: Runoob
data2['url']: http://www.runoob.com
如果你要处理的是文件而不是字符串,你可以使用 json.dump() 和 json.load() 来编码和解码JSON数据。例如:
# 写入 JSON 数据
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取数据
with open('data.json', 'r') as f:
data = json.load(f)