
Linux常用命令
Linux常用命令
1.ls命令
ls -a 列出目录所有文件,包含以.开始的隐藏文件
ls -t 以文件修改时间排序
ls -l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来(简写ll)
2.cd命令
跳转至/usr/bin/
$ cd /usr/bin/
跳转至home目录
$ cd ~
或
$ cd
跳转至根目录
$ cd /
返回进入当前目录前所在目录
$ cd -
跳转至当前目录的上层
$ cd ..
跳转至当前目录的上上层
$ cd ../..
3.mkdir命令
mkdir -p /tmp/test/t1/t 在tmp目录下创建路径为test/t1/t的目录,若不存在,则创建
4.rm命令
删除一个目录中的一个或多个文件或目录,如果没有使用 -r 选项,则 rm 不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状。
rm -i *.log 删除任何.log 文件,删除前逐一询问确认
rm -rf test 删除test子目录及子目录中所有档案删除,并且不用一一确认
5.mv命令
移动文件或修改文件名,根据第二参数类型(如目录,则移动文件;如为文件则重命令该文件)。
mv test.log test1.txt 将文件test.log重命名为test1.txt
mv /test/t2/1.log /test/t1/ 将test目录下t2目录下的1.log文件转移到test目录下的t1目录中
6.cp命令
命令行复制,如果目标文件已经存在会提示是否覆盖,而在 shell 脚本中,如果不加 -i 参数,则不会提示,而是直接覆盖!
-i 提示
-r 复制目录及目录内所有项目
-a 复制的文件与原文件时间一样
cp -i 1.log 2.log 根据1.log文件复制一个名为2.log文件,若2.log文件存在,则提示是否覆盖
cp -r t1 t3 复制t1目录及目录内所有项目到t3目录
7.cat命令
cat filename 一次显示整个文件
cat > filename 从键盘创建一个文件
cat file1 file2 > file 将几个文件合并为一个文件
8.head命令和tail命令
head 1.log -n 20 显示1.log文件中前20行
tail 1.log -n 20 显示1.log文件中后20行
tail -f ping.log 递归显示ping.log文件的末尾,可以用来查看实时日志
9.which命令
which 是在 PATH 就是指定的路径中,搜索某个系统命令的位置,并返回第一个搜索结果。使用 which 命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
which 查看可执行文件的位置。
whereis 查看文件的位置。
locate 配合数据库查看文件位置。
find 实际搜寻硬盘查询文件名称。
which ls 查看ls命令是否存在,执行哪个
10.find命令
命令格式
find pathname -options [-print -exec -ok ...]
命令参数
pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
-print: find命令将匹配的文件输出到标准输出。
-exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为'command' { } \;,注意{ }和\;之间的空格。
-ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
命令选项
-name 按照文件名查找文件
-perm 按文件权限查找文件
-user 按文件属主查找文件
-group 按照文件所属的组来查找文件。
-type 查找某一类型的文件,诸如:
b - 块设备文件
d - 目录
c - 字符设备文件
l - 符号链接文件
p - 管道文件
f - 普通文件
-size n :[c] 查找文件长度为n块文件,带有c时表文件字节大小
-amin n 查找系统中最后N分钟访问的文件
-atime n 查找系统中最后n*24小时访问的文件
-cmin n 查找系统中最后N分钟被改变文件状态的文件
-ctime n 查找系统中最后n*24小时被改变文件状态的文件
-mmin n 查找系统中最后N分钟被改变文件数据的文件
-mtime n 查找系统中最后n*24小时被改变文件数据的文件
(用减号-来限定更改时间在距今n日以内的文件,而用加号+来限定更改时间在距今n日以前的文件。 )
-maxdepth n 最大查找目录深度
-prune 选项来指出需要忽略的目录。在使用-prune选项时要当心,因为如果你同时使用了-depth选项,那么-prune选项就会被find命令忽略
-newer 如果希望查找更改时间比某个文件新但比另一个文件旧的所有文件,可以使用-newer选项
实例
find -atime -2 查找48小时内修改过的文件
find ./ -name '*.log' 在当前目录查找以.log结尾的文件 .代表当前目录 ->类似于SQL中的模糊查询方式,*可以放前面也可以放后面或者都放
find /opt -perm 777 查找 /opt 目录下 权限为 777 的文件
加exec参数
-exec 参数后面跟的是 command 命令,它的终止是以 ; 为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。{} 花括号代表前面find查找出来的文件名。
find . -type f -mtime +10 -exec rm -f {} \; 在当前目录中查找更改时间在10日以前的文件并删除它们(无提醒)
find . -f -name 'passwd*' -exec grep "pkg" {} \; 当前目录下查找文件名以 passwd 开头,内容包含 "pkg" 字符的文件
11.chmod命令
用于改变 linux 系统文件或目录的访问权限,该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件所有者的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。可使用ls -l filename查询权限信息。如图

上图中文件所有者(属主)为root,所有组(属组)为root,文件名为install.log,权限位的第一个减号“-”代表的是文件类型: -:普通文件,d:目录文件,l:链接文件,b:设备文件,c:字符设备文件,p:管道文件
实例
-rw-r--r-- 1 root root 296K 11-13 06:03 log2012.log
第一列共有 10 个位置,第一个字符指定了文件类型。在通常意义上,一个目录也是一个文件。如果第一个字符是横线,表示是一个非目录的文件。如果是 d,表示是一个目录。从第二个字符开始到第十个 9 个字符,3 个字符一组,分别表示了 3 组用户(文件所有者、跟所有者同组的用户、其他用户)对文件或者目录的权限。权限字符用横线代表空许可,r 代表只读,w 代表写,x 代表可执行。
数字设定法(常用)
读(read),写(write),执行r(recute)简写即为(r,w,x),亦可用数字来(4,2,1)表示

举例:如果某文件
权限为7则代表可读、可写、可执行(4+2+1).
权限为6(4+2)则代表可读、可写。
权限为5代表可读(4)和可执行(1)。
权限为3代表可写(2)和可执行(1)。
实例
chmod 777 1.log 给1.log文件的属主、属组、其他用户分配可读、可写、可执行权限 ———————————— 执行完成后查看权限信息: -rwxrwxrwx 1 root root 4 Jul 5 15:25 1.log
chmod 751 1.log 给1.log文件的属主分配rwx(读、写、执行)权限,属组wx(读、执行)权限,其他用户x(执行)权限 ———————————— 执行完成后查看权限信息:-rwxr-x--x 1 root root 6 Jul 6 15:36 1.log
12.chown命令
chown 将指定文件的所有者、所属组进行更改;文件是以空格分开的要改变权限的文件列表,支持通配符。
-c 显示更改的部分的信息
-R 处理指定目录及子目录
chown -c mail:mail 1.log 将1.log文件的所有者、所属组更改为mail
chown -c :mail 1.log 将1.log文件的所属组更改为mail
chown -cR mail: test/ 改变文件夹及子文件目录所属主及所属组为mail
vi /etc/group 可以查看用户所在的组
13.tar命令
用来压缩和解压文件
-c 建立新的压缩文件
-v 显示操作过程
-f 指定压缩文件
-z 支持gzip压缩 -j 支持bzip2压缩
-x 从压缩包中抽取文件
14.df命令
获取硬盘被占用了多少空间,目前还剩下多少空间等信息,如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。
df -l 显示磁盘使用情况
15.du命令
du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看
-a 显示目录中所有文件大小
-k 以KB为单位显示文件大小
-m 以MB为单位显示文件大小
-g 以GB为单位显示文件大小
-h 以易读方式显示文件大小
-s 仅显示总计
-c或--total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件
du -h scf/ 以易读方式显示文件夹内及子文件夹大小
du -hc test/ scf/ 显示几个文件或目录各自占用磁盘空间的大小,还统计它们的总和
du -hc --max-depth=1 scf/ 输出当前目录下各个子目录所使用的空间
16.free命令
显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。
-b 以Byte显示内存使用情况
-k 以kb为单位显示内存使用情况
-m 以mb为单位显示内存使用情况
-g 以gb为单位显示内存使用情况
-s<间隔秒数> 持续显示内存
-t 显示内存使用总合
free
17.top命令
显示当前系统正在执行的进程的相关信息,包括进程 ID、内存占用率、CPU 占用率等
各进程(任务)的状态监控,项目列信息说明如下
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
18.vmstat命令
vmstat,是linux中最常见的监控小工具,用来展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情。

命令参数:
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
vmsat 1 5 :表示1s中采集一次,一共采集5次
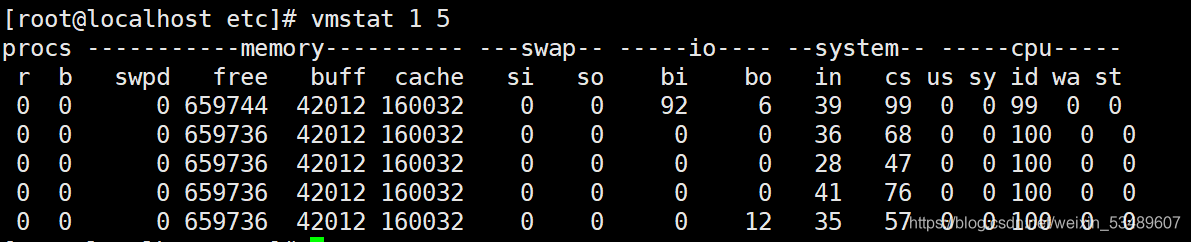
Procs列
r: 等待访问CPU进程数量 也就是运行队列 当这个值超过了CPU数目,就会出现CPU瓶颈了
b: 睡眠进程的数量 也就是阻塞队列
Memory列
swpd: 虚拟内存已使用的大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。
free: 空闲的物理内存的大小,大小为kb
buff: 存储,目录里面的内容,权限等的缓存
cache: 存储我们打开的文件,给文件做缓冲,如果cache的值大的时候,说明cache处的文件数多,如果频繁访问到的文件都能被cache处,那么磁盘的读IO bi会非常小。
Swap列
si: 每秒从交换区写到内存的大小,由磁盘调入内存。(In)
so: 每秒写入交换区的内存大小,由内存调入磁盘。(Out)
注意:
内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响,磁盘IO和CPU资源都会被消耗。
有些朋友看到空闲内存(free)很少的或接近于0时,就认为内存不够用了,不能光看这一点,还要结合si和so,如果free很少,但是si和so也很少(大多时候是0),那么不用担心,系统性能这时不会受到影响的。
I/O列
bi: 每秒读取的块数
bo: 每秒写入的块数
注意:随机磁盘读写的时候,这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。
System列
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
注意:上面2个值越大,会看到由内核消耗的CPU时间会越大
CPU(以百分比表示):
us: 用户进程执行时间(user time)
注意:us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。
sy: 系统进程执行时间(system time)
注意:sy的值高时,说明系统内核消耗的CPU资源多,我们应该检查原因,此时可能有很多系统调用,才用strace,pstack可以继续审图查找
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
备注:
如果 r经常大于4,且id经常少于40,表示cpu的负荷很重。
如果pi,po 长期不等于0,表示内存不足。
如果disk 经常不等于0, 且在 b中的队列 大于3, 表示 io性能不好。
如果in较高cs较低,说明cpu一直在请求资源
如果us在80%一上而且cs比较低 说明某个进程一直在占用cpu。
如果cs比in高很多说明上下文切换很多 进一步sy比us高很多 则说明正在运行的程序进行了大量的系统调用
19.iostat命令
1.iostat iostat用来动态监视系统的磁盘操作活动。通过iostat方便查看CPU、网卡、tty设备、磁盘等设备的活动情况和负载信息。 命令:iostat [参数] [采样间隔时间秒数] [采样次数] 例如:
iostat -cm -d 2 10 -x //监控CPU&磁盘的详细信息,2秒间隔总计10次
iostat -cm -d 2 10 //监控CPU&磁盘的简要信息,2秒间隔总计10次,会显示tps
iostat参数:
-c 显示CPU使用情况
-d 显示磁盘使用情况
-k 以 KB 为单位显示
-m 以 M 为单位显示
-N 显示磁盘阵列(LVM) 信息
-n 显示NFS 使用情况
-p[磁盘] 显示磁盘和分区的情况
-t 显示终端和CPU的信息
-x 显示详细信息
-V 显示版本信息
输出的常用属性值介绍
输出的常用属性值介绍
CPU属性值:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带nice值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲(无IO请求处理)时间百分比。
说明:
1)如果%iowait的值过高,表示硬盘存在I/O瓶颈;
2)如果%idle的值过高,表示CPU较空闲;
3)如果%idle的值较高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量;
4)如果%idle的值持续低于10,那么系统的CPU处理能力相对较低,表明系统中最突出需要解决的资源是CPU。
TPS&吞吐量属性值:
tps:设备每秒的传输次数。一次传输是指一次I/O请求。多个逻辑请求可能会被合并为一次I/O请求。一次传输请求的大小是未知的。
kB_read/s:每秒从设备读取的数据量。
kB_wrtn/s:每秒向设备写入的数据量。
kB_read:读取的总数据量。
kB_wrtn:写入的总数量数据量。
磁盘属性值:
rrqm/s: 每秒进行merge的读操作数目。即rmerge/s。
wrqm/s: 每秒进行merge的写操作数目。即wmerge/s。
r/s: 每秒完成的读I/O设备次数。即rio/s。
w/s: 每秒完成的写I/O设备次数。即wio/s。
rsec/s: 每秒读扇区数。即rsect/s。
wsec/s: 每秒写扇区数。即wsect/s。
rkB/s: 每秒读K字节数。是rsect/s的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是wsect/s的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度,相当于单位时间里平均排队的个数。
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于I/O操作,即被IO消耗的cpu百分比。也可以理解为一秒中有多少时间I/O队列是非空的。
说明:
1)如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,磁盘可能存在瓶颈;
同时可以结合vmstat查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力较高)。
注意:
IOPS:IO per Second,IO系统每秒所执行IO操作的次数。
IO的响应时间的增长是非线性的,IO越是接近最大值,响应时间就变得越大,而且会比预期超出很多。
一般来说在实际的应用中有一个70%的指导值。也就是说在IO读写的队列中,当队列大小小于最大IOPS的70%的时候,IO的响应时间增加会很小,一般都能接受。
一旦超过70%,响应时间就会戏剧性的暴增。
所以当一个系统的IO压力超出最大可承受压力的70%的时候,就是必须要考虑优化或升级。
这个70%的指导值也适用于CPU响应时间,实践中证明,一旦CPU超过70%,系统将会变得比较慢。
2)await一般要和svctm联合起来分析。
await的大小一般取决于服务时间(svctm)以及I/O队列的长度和I/O请求的发出模式。
svctm的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致svctm的增加。
svctm一般要小于await,因为同时等待的请求的等待时间被重复计算了。
如果svctm接近await,说明I/O几乎没有等待时间。
如果await远大于svctm(差值较高),说明I/O队列太长,IO响应太慢,应用得到的响应时间太慢。如果用户不能容忍,则必须进行优化。可以考虑更换更快的磁盘、优化应用或升级CPU。
3)如果avgqu-sz较大,说明有大量的IO在等待。
如果avgqu-sz较小,即使r/s+w/s很大,说明这些I/O请求比较均匀,大部分处理还是比较及时的。
avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s。也就是说读写速度是这个来决定的。
[root@myoracle ~]# iostat -cdm 2 2 -x
Linux 3.10.0-327.el7.x86_64 (myoracle) 03/27/2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.43 0.00 0.46 1.05 0.00 97.05
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.04 6.68 9.93 307.84 0.92 13.91 95.60 0.14 0.45 4.81 0.31 0.27 8.68
dm-0 0.00 0.00 10.08 314.52 0.92 13.91 93.58 0.17 0.51 4.87 0.38 0.27 8.66
avg-cpu: %user %nice %system %iowait %steal %idle
4.75 0.00 2.98 9.25 0.00 83.02
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 4054.00 0.00 105.63 53.36 0.85 0.21 0.00 0.21 0.19 77.50
dm-0 0.00 0.00 0.00 4054.00 0.00 105.63 53.36 0.86 0.21 0.00 0.21 0.19 77.65
[root@myoracle ~]# iostat -cdm 2 2
Linux 3.10.0-327.el7.x86_64 (myoracle) 03/27/2019 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.44 0.00 0.47 1.06 0.00 97.04
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 321.41 0.92 14.02 3485 53182
dm-0 328.23 0.92 14.02 3483 53182
avg-cpu: %user %nice %system %iowait %steal %idle
10.26 0.00 4.43 8.99 0.00 76.31
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 3847.00 0.00 140.00 0 280
dm-0 3847.00 0.00 140.00 0 280
20.ifstat命令
ifstat是个网络接口监测工具,可以方便的查看网络流量信息。 命令:ifstat [interfaceName]
# ifstat eth0
#kernel
Interface RX Pkts/Rate TX Pkts/Rate RX Data/Rate TX Data/Rate
RX Errs/Drop TX Errs/Drop RX Over/Rate TX Coll/Rate
eno16777984 178728 0 11014 0 270412K 0 729576 0
0 0 0 0 0 0 0 0
21.iftop命令
iftop是一款实时流量监控工具,监控TCP/IP连接等,必须以root身份才能运行。
iftop -i eth0
通过iftop的界面很容易找到哪个ip在网络流量占用情况,流量单位是Mb,这个和ifstat的KB有区别。
22.iotop命令
查看哪个进程使用硬盘最多
23.touch命令
用来创建文件,用来修改文件的时间戳。
命令参数
-a 或–time=atime或–time=access或–time=use 只更改存取时间。
-c 或–no-create 不建立任何文档。
-d 使用指定的日期时间,而非现在的时间。
-f 此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题。
-m 或–time=mtime或–time=modify 只更改变动时间。
-r 把指定文档或目录的日期时间,统统设成和参考文档或目录的日期时间相同。
-t 使用指定的日期时间,而非现在的时间。
A n --after-context显示匹配字符后n行
-B n --before-context显示匹配字符前n行
-C n --context 显示匹配字符前后n行
-c --count 计算符合样式的列数
-i 忽略大小写
-l 只列出文件内容符合指定的样式的文件名称
-f 从文件中读取关键词
-n 显示匹配内容的所在文件中行数
-R 递归查找文件夹
24.wc命令
统计指定的文件中字节数、字数、行数,并将统计结果输出
-c 统计字节数
-l 统计行数
-m 统计字符数
-w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
wc text.txt 查找文件的 行数 单词数 字节数 文件名
25.ps命令
用来查看当前运行的进程状态,一次性查看,如果需要动态连续结果使用 top
ps 工具标识进程的5种状态码
D 不可中断 uninterruptible sleep (usually IO)
R 运行 runnable (on run queue)
S 中断 sleeping
T 停止 traced or stopped
Z 僵死 a defunct (”zombie”) process
ps -ef 显示当前所有进程环境变量及进程间关系
ps -A 显示当前所有进程
ps -aux 查看进程
-a 显示除控制进程(session leader)和无终端进程外的所有进程
-A 显示所有进程
-e 此参数的效果和指定-A参数相同
-f 显示完整格式的输出
-u<用户识别码> 列出属于该用户的进程的状况,也可使用用户名称来指定
-L 显示进程中的线程
-l 显示长列表
a 显示跟任意终端关联的所有进程
u 采用基于用户的格式显示
x 显示所有的进程,甚至包括未分配任何终端的进程
26.kill命令
终止指定进程
kill name
kill -9 3306 杀死mysql 进程 ——强制杀死
27.netstat命令
查看网络状态、端口状态
实例
netstat -tunlp|grep 端口号
-t : 指明显示TCP端口
-u : 指明显示UDP端口
-l : 仅显示监听套接字(LISTEN状态的套接字)
-p : 显示进程标识符和程序名称,每一个套接字/端口都属于一个程序
-n : 不进行DNS解析
-a 显示所有连接的端口
28.lsof命令
sof的作用是列出当前系统打开文件(list open files),不过通过-i参数也能查看端口的连接情况,-i后跟冒号端口可以查看指定端口信息,直接-i是系统当前所有打开的端口
lsof -i:22 #查看22端口连接情况
netstat -an|grep 8080 lsof -i:8080
区别: 1.netstat无权限控制,lsof有权限控制,只能看到本用户 2.losf能看到pid和用户,可以找到哪个进程占用了这个端口
28.ifconfig命令
用于查看和配置网络接口。
29.ping命令
ping命令是用于排除故障,测试和诊断网络连接问题
30.pwd命令
获取当前工作目录的 绝对路径
31.touch命令
用来创建文件,用来修改文件的时间戳。
命令参数
-a 或–time=atime或–time=access或–time=use 只更改存取时间。
-c 或–no-create 不建立任何文档。
-d 使用指定的日期时间,而非现在的时间。
-f 此参数将忽略不予处理,仅负责解决BSD版本touch指令的兼容性问题。
-m 或–time=mtime或–time=modify 只更改变动时间。
-r 把指定文档或目录的日期时间,统统设成和参考文档或目录的日期时间相同。
-t 使用指定的日期时间,而非现在的时间。
创建一个1.txt文件 > touch 1.txt
创建多个文件 > touch file1 file2
32.rm命令
rm删除文件或目录,删除后不能恢复,加I参数以逐个确认要删除的文件
rm -r abc
33.ln命令
ln命令用于给文件创建链接
软链接:类似于 Windows 系统中给文件创建快捷方式,即产生一个特殊的文件,该文件用来指向另一个文件,此链接方式同样适用于目录。
硬链接:我们知道,文件的基本信息都存储在 inode 中,而硬链接指的就是给一个文件的 inode 分配多个文件名,通过任何一个文件名,都可以找到此文件的 inode,从而读取该文件的数据信息。
选项:
-s:建立软链接文件。如果不加 "-s" 选项,则建立硬链接文件;
-f:强制。如果目标文件已经存在,则删除目标文件后再建立链接文件;
【例 1】创建硬链接:
[root@localhost ~]# touch cangls
[root@localhost ~]# ln /root/cangls /tmp
#建立硬链接文件,目标文件没有写文件名,会和原名一致
#也就是/tmp/cangls 是硬链接文件
【例 2】创建软链接:
[root@localhost ~]# touch bols
[root@localhost ~]# In -s /root/bols /tmp
#建立软链接文件
软链接文件的源文件必须写成绝对路径,而不能写成相对路径(硬链接没有这样的要求);否则软链接文件会报错。
硬链接的特点:
不论是修改源文件(test 文件),还是修改硬链接文件(test-hard 文件),另一个文件中的数据都会发生改 变。
不论是删除源文件,还是删除硬链接文件,只要还有一个文件存在,这个文件(inode 号是 262147 的文件) 都可以被访问。
硬链接不会建立新的 inode 信息,也不会更改 inode 的总数。
硬链接不能跨文件系统(分区)建立,因为在不同的文件系统中,inode 号是重新计算的。
硬链接不能链接目录,因为如果给目录建立硬链接,那么不仅目录本身需要重新建立,目录下所有的子文件,包括 子目录中的所有子文件都需要建立硬链接
软链接的特点
不论是修改源文件(check),还是修改硬链接文件(check-soft),另一个文件中的数据都会发生改变。
删除软链接文件,源文件不受影响。而删除原文件,软链接文件将找不到实际的数据,从而显示文件不存在。
软链接会新建自己的 inode 信息和 block,只是在 block 中不存储实际文件数据,而存储的是源文件的文件 名及 inode 号。
软链接可以链接目录。
软链接可以跨分区。
34.rpm命令
软件包的管理
查询已安装的rpm列表:rpm -qa
/ rpm -qa | grep xx
查询软件包是否安装:rpm -q 软件包名
查询软件包的信息:rpm -qi 软件包名
卸载:rpm -e rpm包名
安装:rpm -ivh rpm包名(i-install(安装)、v-verbose(提示)、h-hash(进度条))
参数
命令 作用
-a 查询所有套件;
-b<完成阶段><套件档>+或-t <完成阶段><套件档>+ 设置包装套件的完成阶段,并指定套件档的文件名称;
-c 只列出组态配置文件,本参数需配合"-l"参数使用;
-d 只列出文本文件,本参数需配合"-l"参数使用;
-e<套件档>或–erase<套件档> 删除指定的套件;
-f<文件>+ 查询拥有指定文件的套件;
-h或–hash 套件安装时列出标记;
-i 显示套件的相关信息;
-i<套件档>或–install<套件档> 安装指定的套件档;
-l 显示套件的文件列表;
-p<套件档>+ 查询指定的RPM套件档;
-q 使用询问模式,当遇到任何问题时,rpm指令会先询问用户;
-R 显示套件的关联性信息;
-s 显示文件状态,本参数需配合"-l"参数使用;
-U<套件档>或–upgrade<套件档> 升级指定的套件档;
-v 显示指令执行过程;
-vv 详细显示指令执行过程,便于排错。
–force 强制安装
–nodeps 忽略依赖;安装此包需要依赖,如果你不需要这些依赖可以忽略依赖,强制安装
34.yum命令
安装软件包:
yum install package
yum localinstall package 从本机目录安装软件包
yum groupinstall group 安装某个组件的全部软件包
2.更新软件包:
yum update package
yum check-update 列出所有可更新的软件包
yum list updates mysql* 查找mysql的更新
yum update 更新所有可更新的软件包
yum update mysql* 更新所有mysql的软件包
yum groupupdate group 更新某个组件的所有软件包
yum list 列出所有已安装和仓库中可用的软件包
yum list available 列出仓库中所有可用的软件包
yum list updates 列出仓库中比当前系统更新的软件包
yum list installed 列出已安装的软件包
yum list recent 列出新加入仓库的软件包
yum info 查询软件包信息
3.删除软件包:
yum remove package
yum groupremove group 删除某个组件的全部软件包
4.清除软件包
yum clean packages 清除遗留在缓存里的包文件
yum clean metadata 清除遗留在缓存里的元数据
yum clean headers 清除遗留在缓存里的头文件
yum clean all 清除包文件,元数据,头文件
5.搜索软件包:
yum search package
yum info package 查找一个软件包的信息
yum list package 列出包含指定信息的软件包
yum list installed 列出已安装的软件包
yum list extras 列出不是通过软件仓库安装的软件包
yum list *ttp* 列出标题包含ttp的软件包
yum list updates 列出可以更新的软件包
6.查找特定文件是由什么软件包提供的:
yum whatprovides filename
例子:
yum whatprovides httpd.conf
可用选项
–disalberepo=lib 禁用某个软件仓库
–enalberepo=lib 启用某个软件仓库
-C 禁用使用本机缓存的元数据
例子:
yum –disalberepo=livna|–enalberepo=livna install mplayer
yum -C info httpd
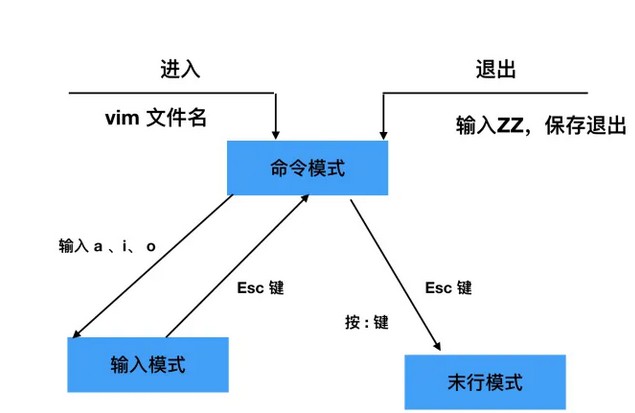
35.vim命令
vim 的工作模式
插入命令:
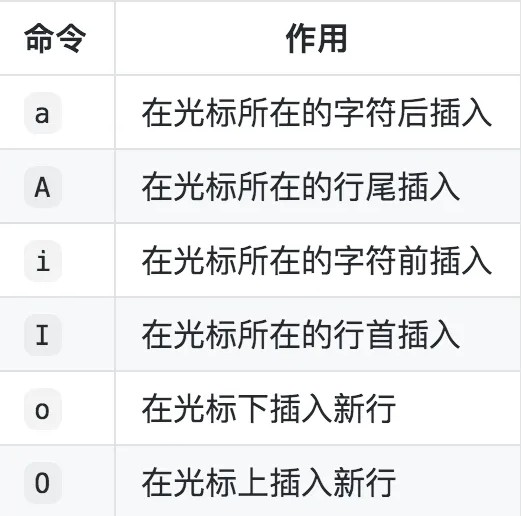
*输入模式:*主要用于文本编辑,和记事本类似,输入数据就好
末行模式(编辑模式):
- :w 保存不退出
- :w 新文件名 把文件另存为新文件
- :q 不保存退出
-:wq 保存退出
-:! 强制
-:q! 强制不保存退出,用于修改文件之后,不保存数据退出
-:wq! 强制保存退出,当文件的所有者或 root 用户,对文件没有写权限的时候,强制写入数据使用
命令模式操作
1、移动光标
1)、上下左右移动光标
上、下、左、右方向键 移动光标
h(左) j(下) k(上) l(右) 移动光标
2)、光标移动到文件头或文件尾
gg 移动到文件头
G 移动到文件尾(shift + g)
3)、光标移动到行首或行尾
^ 移动到行首
$ 移动到行尾
4)、移动到指定行
:n 移动到第几行(这里的 n 是数字)
2、删除或剪切
1)、删除字母
x 删除单个字母
nx 删除 n 个字母(n 是数字,如果打算从光标位置连续删除 10 个字母,可以使用 10x 即可)
2)、删除整行或剪切
dd 删除单行
ndd 删除多行
:n1,n2d 删除指定范围的行
删除行或多行,是比较常用的删除方法。这里的 dd 快捷键既是删除也是剪切。删除内容放入了剪切板,如果不粘贴就是删除,粘贴就是剪切。粘贴方法:
p 粘贴到光标下面一行
P 粘贴到光标上面一行
3)、从光标所在行删除到文件尾
dG 从光标所在行删除到文件尾(d 是删除行,G 是文件尾,连起来就是从光标行删除到文件尾)
3、复制
yy 复制单行
nyy 复制多行
复制之后的粘贴依然可以使用 p 键或 P 键
4、撤销
u 撤销
ctrl + r 反撤销
u 键能一直撤销到文件打开时的状态,ctrl + r 能一直反撤销到最后一次操作状态
5、替换
r 替换光标所在处的字符
R 从光标所在处开始替换字符,按 esc 键结束
导入其他文件的内容
:r 文件名 把文件内容导入到光标位置
:r /root/aa.txt #末行模式下,输入这个会把 /root/aa.txt 文件的内容加到你光标所在处
36.grep命令
grep命令能够在一个或者多个文件中搜索某一特定的字符模式,此模式可以是单一的字符、字符串、单词或句子。grep可以在文本中查找指定的字符串命令能够在一个或者多个文件中搜索某一特定的字符模式,此模式可以是单一的字符、字符串、单词或句子。grep可以在文本中查找指定的字符串
正则表达式的通配符如下
* : 将匹配0个或者多个字符。
. :将匹配任何一个字符,且只能是一个字符。
[xyz] :匹配方括号中的任意一个字符。
[^xyz]:匹配方括号中的任意一个字符。
^ : 锁定行的开头。
$ :锁定行的结尾。
? :匹配前面的子表达式0次或者1次。
+ :匹配前面的子表达式1次或者多次。
| : 匹配于|符号前或后的正则表达式。
{n,m} :最少匹配n次,最多匹配m次和BRE的区别是不需要加\。
在基本的正则表达式中,使用通配符原本的意思,需要添加\作为转义字符。
grep命令格式:`grep [选项] 模式 文件名
这里的模式,要么是字符串,要么是正则表达式。常用的选项如下表。
-A:除了匹配行,额外显示该行之后的N行
-B:除了匹配行,额外显示该行之前的N行
-C:除了匹配行,额外显示该行前后的N行
-c:统计匹配的行数
-e:实现多个选项间的逻辑 or 关系
-E:支持扩展的正则表达式
-F:相当于 fgrep
-i:忽略大小写
-n:显示匹配的行号
-o:仅显示匹配到的字符串
-q:安静模式,不输出任何信息,脚本中常用
-s:不显示错误信息
-v:显示不被匹配到的行
-w:显示整个单词
--color:以颜色突出显示匹配到的字符串
如果是搜索多个文件,grep命令的搜索结果只显示文件中发现匹配模式的文件名,如果搜索单个文件,grep命令的结果将显示每一个包含匹配模式的行。
37.sed命令
sed是一种流编辑器,流编辑器会在编辑器处理数据之前基于预先提供一组规则来编辑数据流。sed编辑器可以根据命令来处理数据流中的数据,这些命令要么从命令行中输入,要么存储在一个命令文本中。
sed命令格式:
sed -e '操作' 文件1 文件2
sed -n -e '操作' 文件1 文件2
sed -f 脚本文件 文件1 文件2
sed -e -i '操作' 文件1 文件2
常用选项:
-e或--expression:表示用指定命令来处理输入的文本文件,只有一个操作命令时可以省略,一般在执行多个操作命令使用。
-f或--file:表示用指定脚本文件来处理输入的文本文件。
-h或--help:显示帮助。
-n或s --quiet:禁止sed编辑器输出,但可以与p命令一起使用完成输出。
-i:直接修改文本文件。
-r,-E:使用扩展正则表达式
-s:将多个文件视为独立文件,而不是单个连续的长文件流。
常用操作:
s:替换指定字符(替换)。
d:删除指定的行(删除)。
a:在指定的行上一行增加一行指定内容(增加)。
i:在指定的上一行插入一行指定内容(插入)。
c:将选定行内容替换为指定内容(替换)。
y:字符转换,转换之后的字符长度必须相同。
p:打印,如果同时指定行,表示打印指定行,如果不指定行,则表示打印所有内容;如果有非打印字符,则以Ascii码输出。通常与_n选项一起使用。
=:打印行号。
l:答应数据流中的文本和不可打印的ASCII字符。
sed的查找
方法一:sed ' ' /etc/shadow
root@chengyan-virtual-machine:~# sed ' ' /etc/shadow
root:$6$lvkzBBp4$EL4M3jGWlhVG73hngVOXVO1o3vtTaLIt7uNrlkC1:19201:0:99999:7:::
daemon:*:17379:0:99999:7:::
bin:*:17379:0:99999:7:::
sys:*:17379:0:99999:7:::
sync:*:17379:0:99999:7:::
games:*:17379:0:99999:7:::
man:*:17379:0:99999:7:::
lp:*:17379:0:99999:7:::
mail:*:17379:0:99999:7:::
方法二:sed -n 'p ' /etc/shadow
root@chengyan-virtual-machine:~# sed -n 'p ' /etc/shadow
root:$6$lvkzBBp4$EL4M3jGWlhVG73hngVOXVO1o3vtTaLIt7uNrlkC1:19201:0:99999:7:::
daemon:*:17379:0:99999:7:::
bin:*:17379:0:99999:7:::
sys:*:17379:0:99999:7:::
sync:*:17379:0:99999:7:::
games:*:17379:0:99999:7:::
man:*:17379:0:99999:7:::
lp:*:17379:0:99999:7:::
mail:*:17379:0:99999:7:::
查看指定行:
root@chengyan-virtual-machine:~# sed -n '3p' /etc/shadow
bin:*:17379:0:99999:7:::
使用正则表达式:匹配root开头的行
root@chengyan-virtual-machine:~# sed -n '/^root/p' /etc/shadow
root:$6$lvkzBBp4$EL4M3jGWlhVG73hngVOXVO1o3vtTaLIt7uNrlkC1:19201:0:99999:7:::
查看连续的行:查看3-6行的内容
root@chengyan-virtual-machine:~# sed -n '3,6p' /etc/shadow
bin:*:17379:0:99999:7:::
sys:*:17379:0:99999:7:::
sync:*:17379:0:99999:7:::
games:*:17379:0:99999:7:::
查看文件最后一行内容:
root@chengyan-virtual-machine:~# sed -n '$p' /etc/shadow
sshd:*:18964:0:99999:7:::
sed的删除
删除指定行并不是真正的删除,知识将删除了的结果显示出来,并不是真正的删除了文件中的内容,如果想要真正的删除文件中的内容需要添加选项-i。
删除文本中的空行:sed '/^$/d' test.txt
root@chengyan-virtual-machine:~# cat -n test.txt
1
2 1
3 2
4 3
5 4
6
7 6
8 7
9 8
10 9
11
root@chengyan-virtual-machine:~# sed '/^$/d' test.txt
1
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~#
删除指定行:
root@chengyan-virtual-machine:~# cat -n test.txt
1
2 1
3 2
4 3
5 4
6
7 6
8 7
9 8
10 9
11
root@chengyan-virtual-machine:~# sed '2d' test.txt
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~#
sed的替换
命令格式:sed 指定行 's/需要替换的字符串/替换后的字符串/替换标记'或者[address]s/pattern/replacement/flag
flag标记:
g:表示要替换所有匹配的行。
w:将替换后的结果保存到文档。
n:1-512,表示指定要替换的字符串出现第几次时才进行替换。
w file:将缓冲区中的内容写到指定的file文件中。
&:用正则表达式匹配的内容进行替换。
\n:匹配第n个子串,该子串之前在pattern中用\(\)指定。
\:转义。
将文件中的test替换为taget:
root@chengyan-virtual-machine:~# cat test1.txt
This is a test file to test replace sed command.
root@chengyan-virtual-machine:~# sed 's/test/taget/g' test1.txt
This is a taget file to taget replace sed command.
root@chengyan-virtual-machine:~#
sed的增加
在第二行下方增加
root@chengyan-virtual-machine:~# cat test.txt
1
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~# sed '2a ######' test.txt
1
######
2
3
4
6
7
8
9
root@chengyan-virtual-machine:~#
38.awk命令
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据进行分析并产生报告时,显得尤为强大。把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分在进行各种分析处理。
awk选项
命令格式:awk [选项] '脚本命令' 文件名
常用选项:
-F fs:指定以fs作为输入行的分隔符,awk命令默认分隔符为空格或者制表符。
-f file:从脚本文件中读取awk脚本指令,以取代直接在命令行中输入指令。
-v var=val:在执行处理过程之前,设置一个变量var,并给其设备的初始值为val。
awk的强大在于脚本命令,有两部分组成,分别是匹配规则和执行命令。
匹配规则{执行命令}
匹配规则用来指定脚本命令可以作用到文本内容中的具体行,可以使用字符串或者正则表达式指定。
整个脚本命令是用单引号括起来,而其中的执行命令部分需要用大括号括起来。
root@chengyan-virtual-machine:~# cat test.txt 1 2 3 4 6 7 8 9 root@chengyan-virtual-machine:~# awk '/^$/{print "Blank line"}' test.txt Blank line Blank line Blank line root@chengyan-virtual-machine:~#其中,/^$/是一个正则表达式,功能是匹配文本中的空白行,同时可以看到,执行命令使用的是print命令,此命令的功能是将指定的文本进行输出。
awk的主要特性之一就是处理文本文件中数据的能力,它会自动给一行中的每个数据元素分配一个变量。默认情况下,awk会将如下变量分配给它在文本行中发现的数据字段。
$0代表整个文本行。 $1代表文本行中的第一个数据字段。 $2代表文本行中的第二个数据字段。 $n代表文本行中的第n个数据字段。awk默认的字段分割符是任意的空白字符,在文本行中,每个数据字段都是通过子弹分割符换分的。awk在读取一行文本时,会用预定的字段分隔符换分每个数据字段。
root@chengyan-virtual-machine:~# cat data.txt One line of test txt. Two lines of test txt. Three lines of test text. root@chengyan-virtual-machine:~# awk '{print $1}' data.txt One Two Three root@chengyan-virtual-machine:~#上面只用了
$1字段变量来表示“仅显示每行文本的第一个数据字段”。要读取采用了其他字段分隔符的文件,可以用-F选项手动指定。awk允许将多条命令组合称为一个正常的程序。要在命令行上的程序脚本中使用多条命令,只要在命令之间放个分号即可。
root@chengyan-virtual-machine:~# echo "My name is Rich" | awk '{$4="Christine";print $0}' My name is Christine root@chengyan-virtual-machine:~# awk '{ > $4="Christine"; > print $0 > }' My name is Rich My name is Christine His name is wanghao His name is Christine当用了起始的单引号后,bash shell会使用
>来提示输入更多数据,可以在每行加一条命令,知道输入了结尾的单引号。因为没有在命令行中指定文件名,awk程序需要用户输入获得数据,因此当运行这个程序的时候,会一直等待用户输入文本,此时如果要退出程序,只需要输入CTRL+D即可root@chengyan-virtual-machine:~# cat awk.sh {print $1"'s home directory is " $6} root@chengyan-virtual-machine:~# awk -F : -f awk.sh /etc/passwd root's home directory is /root daemon's home directory is /usr/sbin bin's home directory is /bin sys's home directory is /dev sync's home directory is /bin games's home directory is /usr/games man's home directory is /var/cache/man在脚本文件中,可以指定多条命令,只要一条命令放在一行就行.
关键字 BEGIN
awk中还可以指定脚本命令运行的时机,默认情况下,awk会从输入中读取一行文本,然后针对该行的数据执行程序脚本,但有时可能需要在处理数据前运行一些脚本命令,这就需要使用BEGIN关键字。
BEGIN关键字会强制awk在读取数据前执行该关键字后指定的脚本命令。
root@chengyan-virtual-machine:~# awk 'BEGIN{print "The data file contents:"} > {print $0}' data.txt The data file contents: One line of test txt. Two lines of test txt. Three lines of test text. root@chengyan-virtual-machine:~#这个脚本命令分为两部分,BEGIN部分的脚本指令会在awk命令处理函数前运行,而真正用来处理数据的是第二段脚本命令。
END
END关键字允许指定一些脚本命令,awk会在读取完数据后执行。
root@chengyan-virtual-machine:~# awk 'BEGIN{print "The data file contents:"} {print $0} END{print "End of file"}' data.txt The data file contents: One line of test txt. Two lines of test txt. Three lines of test text. End of file root@chengyan-virtual-machine:~#变量
在awk脚本程序中,支持使用变量来存取值,awk支持两种不同类型的变量,即内建变量和自定义变量。
内建变量是awk本身就创建好的,用户可以直接使用的变量,这些变量用来存放处理数据文件中的某些字段和记录的信息。自定义变量是awk支持用户自己创建的变量。
常见的内建变量包括数据字段变量($0,$1,$2,....)和其他变量。
字符和记录分隔符变量:
FIELDWIDTHS:由空格分割的一列数字,定义了每个数据字段的确切宽度。 FNR:当前输入文档的记录编号,常在有多个输入文档时使用。 NR:输入流的当前记录编号。 FS:输入字段分隔符。 RS:输入记录分隔符,默认为换行符\n。 OFS:输出字段分隔符,默认为空格。 ORS:输出字段分隔符,默认为换行符\n。环境信息变量:
ARGC:命令行参数个数。 ARGIND:当前文件在ARGC中的位置。 ARGV:包含命令行参数的数组。 CONVFMT:数字的转换格式,默认值为%.6g。 ENVIRON:当前shell环境变量及其值组成的关联数组。 ERRNO:当前读取或关闭输入文件发生错误时的系统错误号。 FILENAME:当前输入文档的名称。 FNR:当前数据文件中的数据行数。 IGNORECASE:设成非0值时,忽略awk命令中出现的字符串的字符串大小。 NF:数据文件中的字段总数。 OFMT:数字的输出格式,默认值为%.6g。 RLENGTH:由match函数所匹配的子字符串的长度。 TSTART:由match函数所匹配的子字符串的起始位置。FS/OFS
变量FS和OFS定义了awk如何处理数据流中的数据字段。
root@chengyan-virtual-machine:~# cat data.txt data11,data12,data13,data14,data15 data21,data22,data23,data24,data25 data31,data32,data33,data34,data35 root@chengyan-virtual-machine:~# awk 'BEGIN{FS=",";OFS="-"}{print $1,$2,$3}' data.txt data11-data12-data13 data21-data22-data23 data31-data32-data33 root@chengyan-virtual-machine:~# awk 'BEGIN{FS=",";OFS="--"}{print $1,$2,$3}' data.txt data11--data12--data13 data21--data22--data23 data31--data32--data33 root@chengyan-virtual-machine:~#FIELDWIDTHS
FIELDWIDTHS变量允许用户不依靠字段分隔符来读取记录,数据如果没有设置分隔符,而是放在特定列中,这种情况下,必须设定FIELDWIDTHS变量来匹配数据在记录中的位置。一旦设置了FIELDWIDTH变量,awk就会忽略FS变量,并根据提供的字段宽度来计算字段。
root@chengyan-virtual-machine:~# cat data1.txt 1005.3247596.37 115-2.349194.00 05810.1298100.1 root@chengyan-virtual-machine:~# awk 'BEGIN{FIELDWIDTHS="3 5 2 5"}{print $1,$2,$3,$4}' data1.txt 1005.3247596.37 115-2.349194.00 05810.1298100.1 root@chengyan-virtual-machine:~#一旦设置了FIELWIDTHS变量的值,就不能在改变了,所以并不适用于变长的字段。
RS/ORS
变量RS和ORS定义了awk程序如何处理数据流中的字段,默认情况下,awk将RS和ORS设为换行符。默认的RS值标明,输入数据流中的每行新文本都是一条新纪录。
root@chengyan-virtual-machine:~# cat data2.txt Riley Mullen 123 Main Street Chicago,IL 60601 (312)555-1234 Frank Wiliams 456 Oak Street Indianapolis,IN 46201 (317)555-9876 Haley Snell 4231 Elm Street Detroit,MI 48201 (313)555-4938 root@chengyan-virtual-machine:~# awk 'BEGIN{FS="\n";RS=""}{print $1,$4}' data2.txt Riley Mullen (312)555-1234 Frank Wiliams (317)555-9876 Haley Snell (313)555-4938 root@chengyan-virtual-machine:~#FNR/NR
FNR变量含有当前数据文件中已处理过的记录数,NR变量则含有已处理过的记录总数。
root@chengyan-virtual-machine:~# cat data.txt data11,data12,data13,data14,data15 data21,data22,data23,data24,data25 data31,data32,data33,data34,data35 root@chengyan-virtual-machine:~# awk ' > BEGIN{FS=","} > {print $1, "FNR="FNR, "NR="NR} > END{print "There were",NR,"records processed"}' data.txt data.txt data11 FNR=1 NR=1 data21 FNR=2 NR=2 data31 FNR=3 NR=3 data11 FNR=1 NR=4 data21 FNR=2 NR=5 data31 FNR=3 NR=6 There were 6 records processed root@chengyan-virtual-machine:~#可以发现,当使用一个数据文件作为输入时,FNR和NR的值相同的,如果多个文件同时作为输入时,FNR的值会在处理每个数据文件时被重置,而NR的值则会继续计数知道处理完所有的数据文件